【SAM 2: Segment Anything in Images and Videos】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
(2024.8.1)
SAM引入了一种用于图像快速分割的基础模型,然而,图像只是真实世界的静态快照,其中视觉片段可以表现出复杂的运动,随着多媒体内容的快速增长,现在有很大一部分是用时间维度记录的,特别是在视频数据中。
视频中的分割旨在确定实体的时空范围,这比图像中的分割提出了独特的挑战。由于运动、变形、遮挡、光照变化和其他因素,实体的外观可能发生重大变化。由于摄像机的运动、模糊和较低的分辨率,视频的质量通常比图像低。此外,对大量帧的有效处理是一个关键的挑战。
SAM 2被设计为一个通用模型,适用于视频和图像领域的视觉分割任务。通过使用记忆机制来处理视频帧,从而实现对目标对象的跟踪和分割。模型由原来的三个部分组成变为了由四个部分组成,在原来架构的基础上加入了记忆注意力(Memory Attention)。
图像编码器(Image Encoder):用于提取视频帧的特征表示,采用流式处理方式,以实现实时视频处理。
记忆注意力(Memory Attention):负责将当前帧的特征与过去帧的特征和预测以及任何新的提示结合起来。
提示编码器(Prompt Encoder):能够接受点击、边框或掩码等提示,以定义给定帧中对象的范围。
掩码解码器(Mask Decoder):根据当前帧的提示和或者之前观察到的记忆来预测该帧的分割掩码。
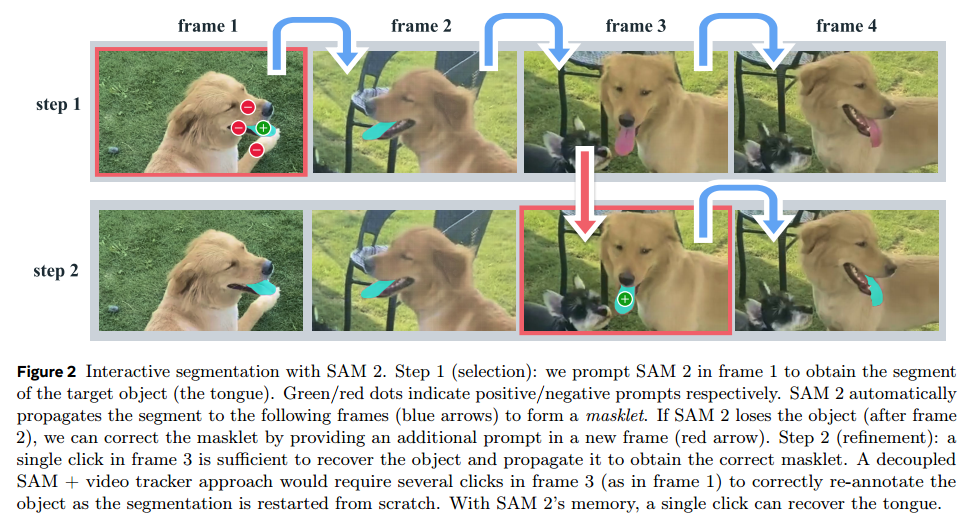
记忆编码器(Memory Encoder)将预测的掩码和图像编码器的特征融合,生成记忆特征。记忆库(Memory Bank)保留有关视频目标对象过去预测的信息,使用先进先出(FIFO)队列来存储记忆。在视频处理中,模型利用记忆来生成整个视频的掩码预测,并根据存储的记忆上下文有效纠正这些预测。
模型在图像和视频数据上进行联合训练,模拟交互式提示,以提高模型对分割任务的准确性。SAM 2 的设计允许它在没有任何先验知识的情况下,通过交互式提示来分割视频中的任何对象。

SAM 2的数据集依然通过数据引擎生成,数据引擎是一个交互式系统,它使用 SAM 2 模型辅助人工标注来标注新的和具有挑战性的数据。与特定类别的对象不同,数据引擎不限制标注的对象类别,而是旨在为分割任何具有有效边界的对象提供训练数据。
数据引擎的三个阶段过程:
阶段 1:使用基于图像的交互式 SAM 辅助人工标注每一帧的视频掩码。
阶段 2:在第一阶段的基础上,引入了 SAM 2 掩码版本,它只接受掩码作为提示,以时间维度上传播掩码。
阶段 3:使用完全功能的 SAM 2,它接受各种类型的提示,包括点和掩码,并利用跨时间维度的对象记忆生成掩码预测。
SAM 2训练所用的 Segment Anything Video (SA-V) 数据集包含50.9K视频和642.6K掩码标注,是目前最大的视频分割数据集。
