【Segment Anything Meets Point Tracking】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
(2023.12.3)
现有的深度神经网络在视频分割上取得了进展,但通常需要昂贵的标注数据来实现高准确率。为了加速数据标注过程,文章提出交互式视频分割方法。
文章提出了一种名为SAM-PT(Segment Anything Meets Point Tracking)的新方法,它结合了SAM和长期点追踪技术,用于交互式视频分割。
SAM-PT是将SAM扩展到视频分割的方法,不需要在任何视频分割数据上训练。
与传统依赖于密集对象掩模传播的视频分割方法不同,SAM-PT引入了一种独特的方法,使用点追踪与SAM结合,SAM被设计为在稀疏点提示上操作。
点追踪与SAM模型有着天然的兼容性,其利用与全局对象语义无关的局部结构上下文,这增强了模型的零样本泛化能力。
SAM-PT分为四个步骤:查询点选择、点追踪、分割和点追踪重初始化。
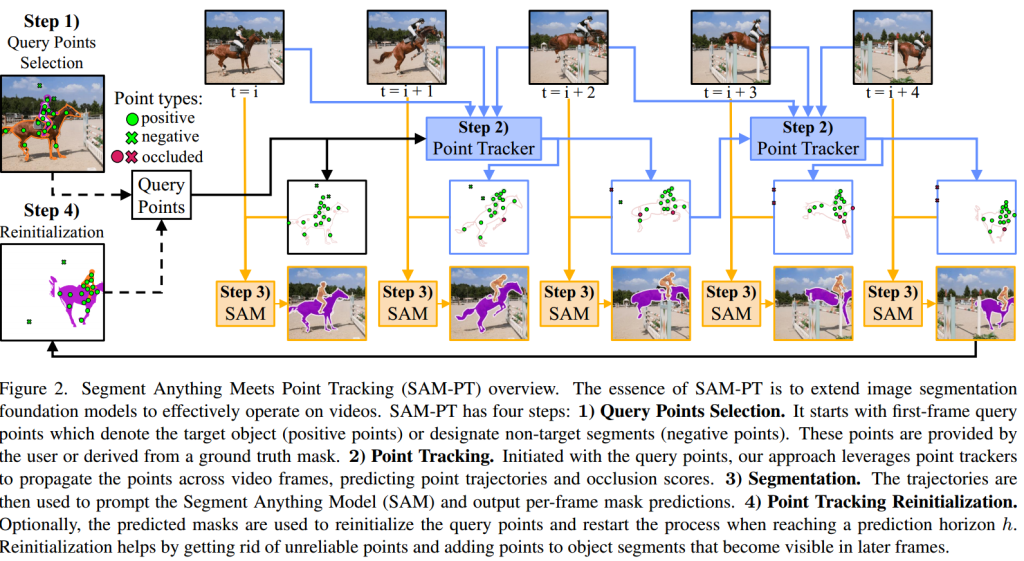
查询点选择(Query Points Selection):在视频的第一帧中定义查询点,这些点可以是目标对象(正点)或背景和非目标对象(负点)。查询点可以由用户手动提供,或从真实掩模中导出。
点追踪(Point Tracker):使用点追踪器将查询点传播到视频的所有帧中,生成点轨迹和遮挡分数。使用的点追踪器包括PIPS和CoTracker,它们对长期追踪挑战(如对象遮挡和重新出现)具有适度的鲁棒性。

分割:利用SAM模型进行分割,使用预测的轨迹中的非遮挡点作为目标对象在整个视频中的位置指示。这些点被用来提示SAM,利用其固有的泛化能力输出每帧的分割掩模预测。与需要在视频分割数据上训练或微调的传统追踪方法不同,SAM-PT在零样本视频分割任务中表现出色。
点追踪重初始化(Reinitialization):当达到预测范围h时,可以选择使用预测掩模重新初始化查询点。这有助于通过丢弃不可靠或被遮挡的点,并在视频中后期可见的对象部分添加点来提高追踪精度。
实验部分:
评估使用了四个视频对象分割(VOS)数据集:DAVIS 2016、DAVIS 2017、YouTube-VOS 2018和MOSE 2023。并从 BDD100K数据集中派生出 VOS 数据集,用于评估。还包括了UVO v1.0 数据集,这是一个视频实例分割(VIS)数据集,旨在进行开放世界分割,识别和分割训练中未见过的任何类别的对象。




