【Self-Prompting Large Vision Models for Few-Shot Medical Image Segmentation】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
(2023.8.15)
论文提出了一种新颖的自提示方法,利用SAM在少量样本的情况下进行医学图像分割。这种方法通过简单的线性像素级分类器,保留了大型模型的编码能力、解码器的上下文信息,并利用其交互式提示能力,在多个数据集上取得了竞争性的结果。
传统的医学图像分析方法依赖于大量的标记数据进行训练。获取这些数据不仅成本高昂,而且由于高质量标记医学数据的稀缺性,这种做法在实践中可能不切实际。
使用简单的线性像素级分类器来自我提示SAM模型,利用大型视觉基础模型的提示特性,通过插入一个小的即插即用单元到SAM中,实现了在有限标记数据和时间内完成所有训练的目标。此方法使用少量图像训练集就能取得良好的结果,性能优于使用相同数据量的其他微调方法。此外,该方法几乎不需要训练,可以在30秒内完成训练。
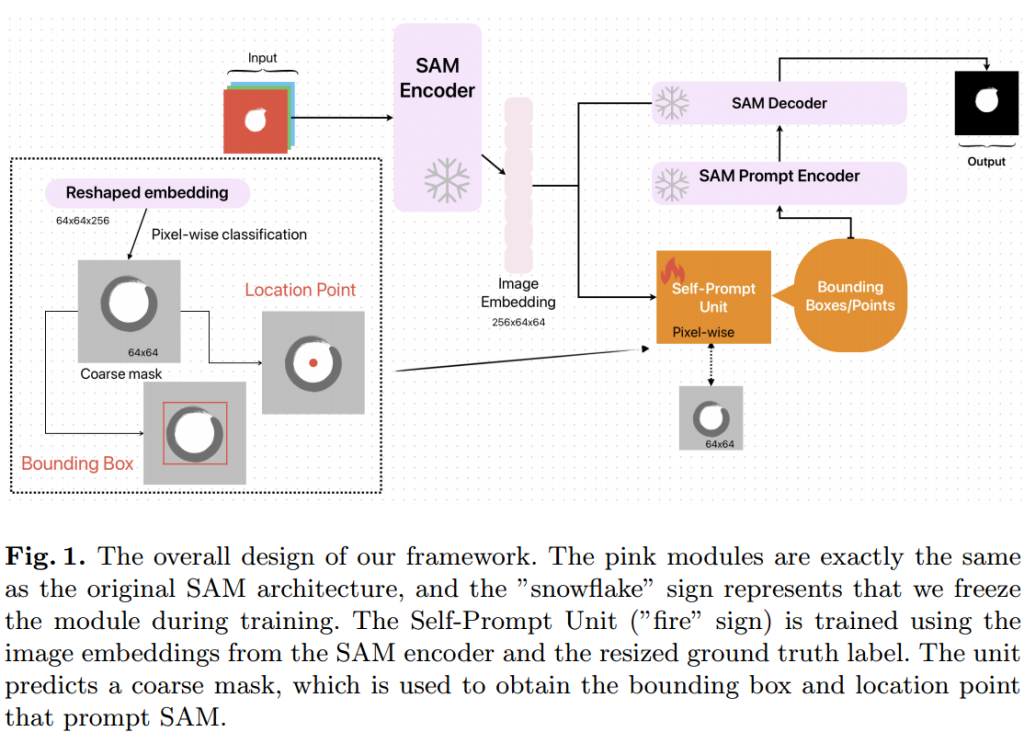
自提示单元:使用粗略掩码作为参考来学习目标的位置和大小信息。输入图像通过SAM的强大编码器(Vision Transformer, ViT)编码为向量。将掩码下采样到64×64并与编码的图像嵌入对齐。使用逻辑回归对每个像素进行分类,得到粗略掩码。使用形态学和图像处理技术从预测的低分辨率掩码中获取位置点和边界框。
使用距离变换找到预测掩码内的一点来表示位置。距离变换是一种计算图像中每个像素到最近边界的距离的图像处理技术。
使用线性像素级分类器生成的预测掩码的最小和最大X、Y坐标来生成边界框,并添加0-20像素的扰动。为了克服线性层输出质量不高的问题,对线性分类器的输出进行腐蚀和膨胀的形态学处理,并使用这些细化的掩码进行提示生成。
实验部分:
将数据集分为5个相等的部分,并应用5折交叉验证来评估文章提出的方法。
数据集有:Kvasir-SEG和ISIC-2018

