【Fast Segment Anything】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
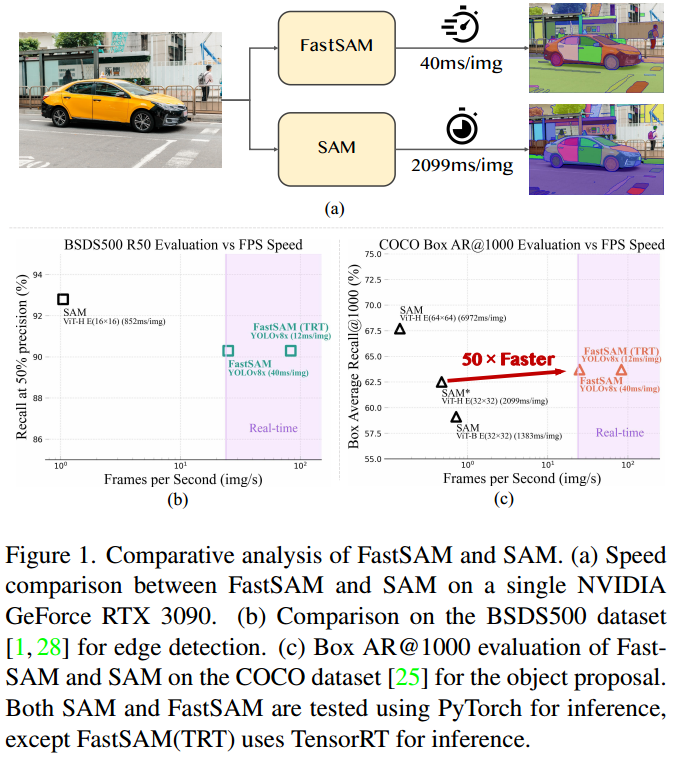
(2023.6.21 武汉大学 https://arxiv.org/abs/2306.12156)
SAM不足之处
虽然SAM模型在分割任务中表现的较为出色,但是由于模型中的Image Encoder部分使用的是比较重的预训练过的Transformer(ViT),所以导致SAM模型在分割图像的时候速度比较慢,无法做到实时分割图像。

模型部分
FastSAM模型主要分为两个过程:全实例分割(All-instance Segmentation)和提示引导选择(Prompt-guided Selection)。
首先全实例分割将图像中的所有对象或区域都分割出来。
再通过点、框、文字(利用CLIP实现)提示选择出来感兴趣的特定对象。
全实例分割部分细节:
- YOLOv8脱胎于YOLOv5,结合了YOLOX、YOLOv6、YOLOv7等相关算法的特点。
- YOLOv8-seg应用YOLACT进行实例分割。YOLOv8-seg首先通过骨干网络(CNN)和特征金字塔(Feature Pyramid Network, FPN)从图像当中提取特征,然后整合不同大小的特征,最后输出检测和分割分支。
- 过程中的PhotoNet从图像中提取特征,然后融合不同尺度的特征,最后结合掩码系数和特征图,生成最终的分割掩码。
提示引导选择部分细节:
- 点提示:在图像上绘制一个或多个点,然后根据点的坐标找到对应坐标相关的特征区域,最后引导模型生成分割掩码。
- 框提示:与点提示类似,在框内坐标找到对应的特征区域生成分割掩码。
- 文本提示:通过CLIP文字编码器将输入的文本转换为特征向量,然后将文本特征向量与图像特征进行匹配,找到与文本描述最相关的图像区域,最后生成对应区域的分割掩码。
文章虽然没有使用SAM模型的架构,但是却取名叫做Fast SAM,因为它的设计思路和SAM相似。主要是它们的提示引导选择部分的做法是相似的。并且Fast SAM模型的训练集是由SAM文章中提出的SA-1B数据集(2%),模型完成的任务目标也类似。
实验
FastSAM使用SA-1B数据集2%的部分进行训练,默认训练次数epoch为100次。并且在边缘检测、对象建议生成(Object Proposal Generation)、实例分割和使用自由格式文本输入分割对象四个模块进行验证。
零样本边缘检测结果


零样本对象建议生成(Object Proposal Generation)结果


零样本实例分割结果

文字提示分割结果

