【Universal Organizer of SAM for Unsupervised Semantic Segmentation】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
(面向无监督语义分割的SAM通用组织器)
(2024.5.20 南京理工大学 https://arxiv.org/abs/2405.11742)
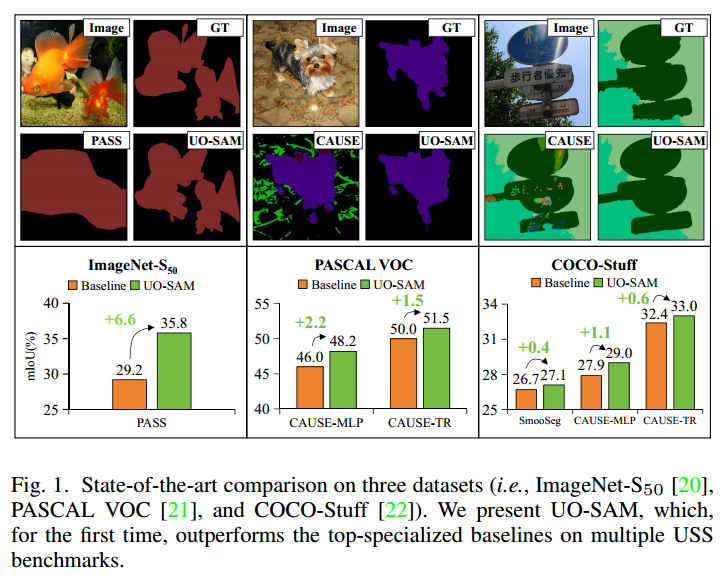
USS(Unsupervised Semantic Segmentation,无监督语义分割)是一种计算机视觉任务,旨在无需人工标注的像素级标签的情况下实现高质量的图像分割。现有的USS模型通常会对区域进行粗略的分类,但其结果往往具有模糊和不精确的边界。文章提出一种基于SAM模型的UO-SAM以提高USS模型的掩码质量。
文章在多个USS数据集进行了广泛的实验评估,结果UO-SAM超越了现有的最先进的方法。文章在SAM的基础上引入了LRO来缓解沿目标边缘的模糊和不清晰的遮罩边界问题,和GRO来保证整体分割的准确性和完整性,从而最大限度地减少不完整的分割实例。

UO-SAM主要由局部区域优化器(LRO)和全局区域优化器(GRO)两个部分构成。
局部区域优化器(LRO):主要做的是优化图像中局部区域的分割掩码。在LRO中使用位置置信度图(LCM)和最大连接组件(LCC)去识别点提示和框提示。
用户只需要提供一个图像I和由无监督语义分割模型生成的掩码M。就可以让UO-SAM自动定位目标对象的位置信息,并以点、边界框或其他视觉提示的形式将其输入提示编码器。可以用SAM的图像编码器提取视觉特征,可以用以下式子表示:


位置置信度图(LCM)的具体实现:
从输入图像I中提取多尺度的局部特征F,然后对提取的局部特征𝐹进行聚类,以识别出具有相似特征的区域,再计算局部特征之间的一致性度量,最后基于一致性度量优化初步生成的分割掩码M,通过调整掩码边界,使得掩码内的像素具有更高的一致性,掩码间的像素具有较低的一致性。用式子表示如下:

最大连接组件(LCC)的具体实现:
先提取图像的局部上下文特征(包括邻域信息、纹理模式),再将局部上下文特征与预先定义的上下文模板进行匹配,然后根据上下文匹配结果,对初步分割掩码进行校准,最后将校准后的掩码与初步掩码融合,生成最终的局部分割掩码。用式子表示如下:

最后通过一致性正则化(Consistency Regularization, CR)来施加一致性约束来提高分割掩码的整体质量。用式子表示如下:

LRO可能会导致模型专注于目标区域,而忽略其他潜在的对象或背景信息。因此,引入GRO来分割整个图像范围,而不仅仅是聚焦于特定的目标物体。

GRO中的IWS(Inconsistency Weighted Sampling)的主要目标是通过加权采样机制来增强无监督语义分割模型的训练效果。CVM(Contextual Voting Mechanism)的主要目标是通过上下文信息进行投票机制来增强分割结果的精确性。
实验部分:
文章使用了三个USS数据集,ImageNet-S50、PASCAL VOC和COCO-Stuff,去验证UO-SAM的性能。

对于ImageNet-S50数据集,文章使用平均交并比(mIoU)、边界mIoU (b-mIoU)、图像级精度(Img-Acc)和F-measure(F-β)作为度量标准。
对于PASCAL VOC和COCO-Stuff,文章使用像素精度(pAcc)和mIoU去衡量模型的性能。
实验结果:




