【Medical SAM Adapter: Adapting Segment Anything Model for Medical Image】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。

(https://arxiv.org/abs/2304.12620 2023.12.29)
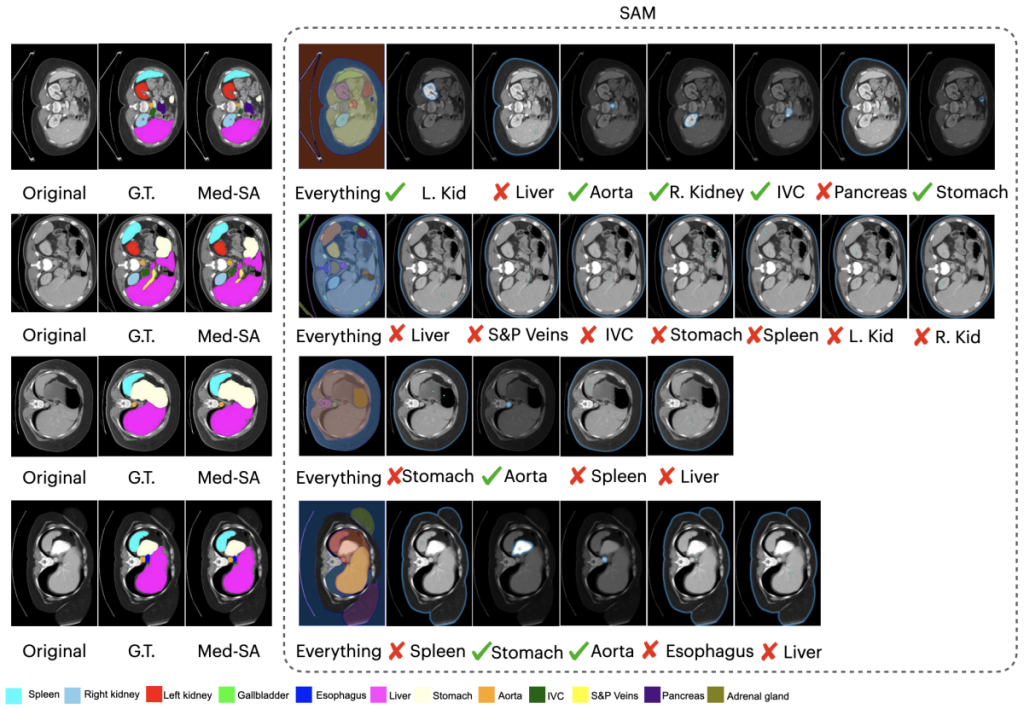
虽然SAM在图像分割领域的表现较好,但是由于缺少医学专业的数据,SAM在医学图像分割方面表现不佳。本篇文章没有对SAM模型进行微调,而是提出了医学SAM适配器(Medical SAM Adapter, Med-SA),该适配器使用一种轻便而有效的适配技术,将特定领域的医学知识纳入分割模型当中。在Med-SA中,文章提出了空间深度转置技术(SD-Trans)来使2D的SAM适应3D的医学图像,并且提出了超提示适配器(hyper-prompt Adapter, hyper-adpt)来实现提示条件适应。最终对17种医学图像分割任务进行了综合评价实验,结果在仅仅更新2%参数的情况下优于目前的医学图像分割方法。
交互式的提示方式可以让临床医生优先考虑感兴趣的领域,可以为他们提供更加个性化的提示方式,极大地帮助临床医生从复杂的结构中有效地区分目标组织。但是由于SAM在医学图像的表现较差,交互式的提示方式也是SAM模型的一个挑战之一。
SAM在医学图像上的有限表现是由于缺乏医学专业知识,包括图像的低对比度、组织边界模糊和病变区域小等挑战。
这个问题的一个解决方式是对SAM模型进行微调,MedSAM(Segment anything in medical images)专门用大量的医疗数据去对SAM模型做微调。但是这对计算和内存占用方面来说都是相当昂贵的。本篇文章也觉得是否有必要对SAM模型做全面的微调也是值得怀疑的,因为预训练的视觉模型对医学影像具有很强的可移植性是在之前的研究中被表明的。
本篇文章使用一种称为自适应的参数有效微调技术(PEFT)对预训练的SAM模型进行微调。
自适应的主要思想是训练时将具有部分参数的适配器模块插入到原始模型中,只更新少量额外的适配器参数的同时保持大型预训练模型的冻结。
自适应技术在自然语言处理(NLP)中被广泛使用,但是将自适应技术直接用在医疗场景中会遇到一些问题和挑战。
第一个问题是不同于二维的自然图像,许多医学图像是三维的,目前尚不清楚如何将二维SAM模型应用于三维医学图像分割。
第二个问题是虽然自适应技术在自然语言处理中取得了成功,但是将其用在视觉模型,特别是SAM等交互式视觉模型的研究还很有限。
第三个问题是如何将用户的可视化提示与适配器结合在一起仍然有待探索。
为了克服上述的挑战,本篇文章提出了医疗SAM适配器(Med-SA)。
在Med-SA中引入了空间深度转置(SD-Trans)技术来实现2D到3D的自适应。
在SD-Trans中,将输入嵌入的空间维度转换为深度转换为深度维度,允许相同的自注意力块在不同的输入下处理不同的维度信息。
然后又提出超提示适配器(hyper-prompt Adapter, hyper-adpt)来实现提示条件适应。其中使用视觉提示生成一系列权重,这些权重可以有效地应用于自适应嵌入,促进广泛和深入的提示-自适应交互。
文章在17种医学图像分割任务中进行了全面的评估,包括CT、MRI、超声图像、fun-dus图像和皮肤镜像图。结果表明Med-SA仅仅通过更新总SAM参数的2%的额外参数就实现了优越的性能,甚至超过的MedSAM的性能。
Med-SA的架构:
Med-SA没有完全调整所有参数,而是保持预训练的SAM参数冻结。
设计一个适配器模块,并将其集成到指定的位置。适配器由向下投影、ReLU激活函数和向上投影组成。向下投影使用简单的MLP层将压缩的嵌入扩展回其原始的维度。

编码器:
如图,第一个适配器被放在多头注意力之后。
第二个适配器被放在MLP层的剩余路径中,跟随多头注意力。
在第二个适配器之后紧跟了一个比例因子s对嵌入进行缩放。 在3D医疗图像的适配器中为每个ViT块合并了三个适配器。第一个适配器用于集成提示的嵌入,为了实现这一目的,还额外引入了一种新的结构超提示适配器(hyper-prompt Adapter, hyper-adpt)。

解码器:
解码器中的第二个适配器与上图中的解码器有完全相同的部署方式,并且使用了hyper-adpt合并提示,以适应MLP增强嵌入。
第三个适配器在实时嵌入到提示交叉注意的残余连接之后部署。
自适应后再进行残差连接和层归一化连接输出最终的结果。
虽然SAM可以应用于一个物体的每个切片以获得最终的分割,但是它没有考虑到三维医学图像分割中固有的紧密的体积相关性。
为了解决这一问题,文章提出SD-Trans来使2D的SAM适应3D的医学图像。如图c,再每个块中,将注意力操作分成了两个分支:空间分支和深度分支。
对于给定深度为D的三维样本,将D × N × L输入到空间分支的多头注意中,其中N表示嵌入数,L表示嵌入长度。这里,D对应于操作的数量,允许在N × L上应用交互,捕获和抽象空间相关性作为嵌入。在深度分支中,将输入矩阵转置以获得N ×D×L,并随后将其馈送到相同的多头注意力中。尽管采用相同的注意机制,交互现在发生在D × L上,使深度相关性的学习和抽象成为可能。最后,将深度分支的结果转置回其原始形状,并将其添加到空间分支的结果中,合并深度信息。
为了在交互模型中将视觉提示整合到适配器中,文章提出了超提示适配器(hyper-prompt Adapter, hyper-adpt),旨在实现快速条件适应。超提示适配器仅利用投影和重塑操作从提示嵌入生成一系列权重图,然后将这些权重图直接应用于适配器嵌入(矩阵乘积)。与生成整个网络相比,这种方法可以实现广泛而深入的特征级交互,同时还显著减少了所需的参数。

实验:
在五种不同的医学图像分割数据集上进行了实验,这些数据集可以分为两类。第一种类型侧重于评估一般分割性能,另外四个任务用于验证模型对不同模式的泛化。


