本文章将接着前一篇关于DeepSeek-R1来更近一步说明其中的关键算法GRPO。本文将大量参考(CV大法)DeepSeek团队在Hungging Face上的GRPO介绍【GRPO 培训师 — GRPO Trainer】。
GRPO是一种在线学习算法(online learning algorithm),这意味着它通过使用训练模型本身在训练期间生成的数据进行迭代改进。GRPO目标背后的直觉是最大限度地利用生成的完成,同时确保模型始终接近参考策略。要了解GRPO的工作原理,可以分为四个主要步骤:生成补全、计算优势、估计 KL 散度和计算损失。
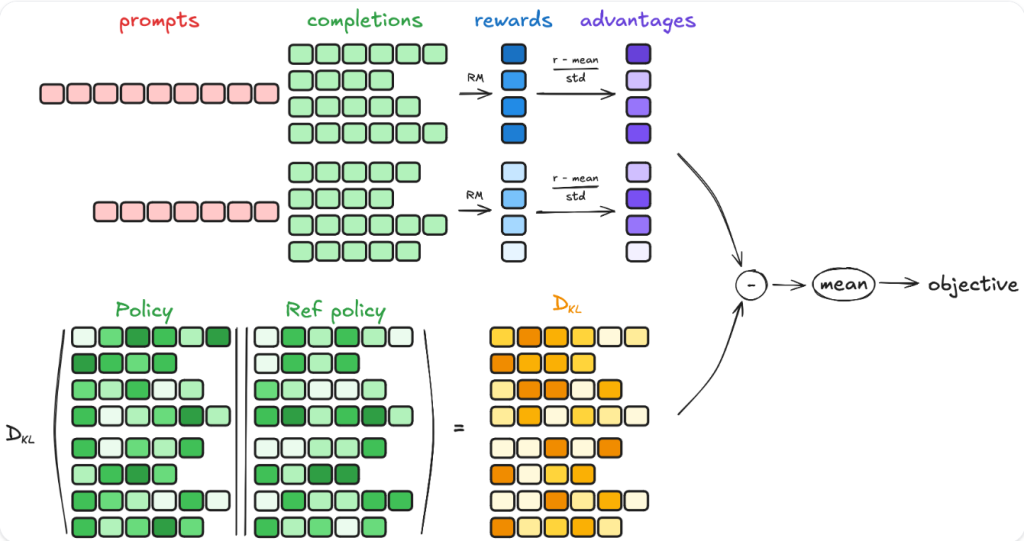
在每个训练步骤中,都会对一批提示进行采样,并为每个提示生成一组G补全(denoted as oi)。
对于每个G序列,使用奖励模型计算奖励。为了与奖励模型的比较性质保持一致(通常在同一问题的输出比较数据集上进行训练),计算优势以反映这些相对比较。它按如下方式规范化:
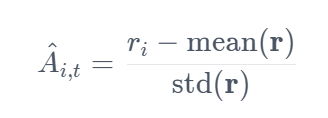
DeepSeek团队将这种组相对策略优化 (GRPO)。
KL 散度是使用 Schulman 等人 (2020) 引入的近似器(approximator)估计的。近似器定义如下:
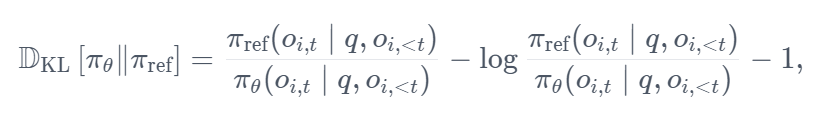
目标是最大限度地发挥优势,同时确保模型始终接近参考策略。因此,损失定义如下:
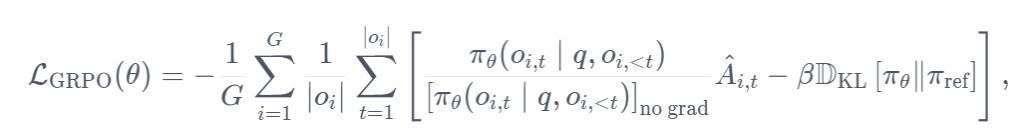
其中,被减的一项代表缩放优势,后一项通过 KL 背离惩罚与参考政策的偏差。
在原始论文中,此公式被推广为通过利用裁剪代理目标来解释每一代之后的多次更新:
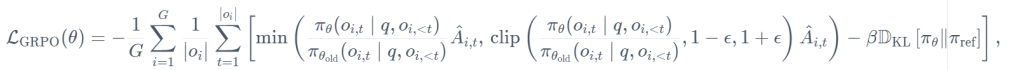
其中 clip(⋅,1−ϵ,1+ϵ)通过将策略比率限制在1+ϵ和1−ϵ之间,确保更新不会过度偏离引用策略。不过,在 TRL 中,就像在原始论文中一样,每一代只进行一次更新,因此可以简化对第一种形式的损失。
为了方便后人使用GRPO进行开发,DeepSeek团队开源了GRPO方法,并为此开发了名为GRPOTrainer的方法(囊括于trl包中),目前GRPO Trainer仍在积极开发当中。其导入方法如下:
from trl import GRPOTrainerGRPO Trainer会记录以下指标:
completion_length:平均完成时长。reward/{reward_func_name}:每个 reward 函数计算的奖励。reward:平均奖励。reward_std:奖励组内的平均标准差。kl: 根据完成次数计算的模型和参考模型之间的平均 KL 散度。
GRPOTrainer支持使用自定义奖励函数,而不是密集的奖励模型。为确保兼容性,奖励函数必须满足以下要求:
- 输入参数
- 返回值:该函数必须返回浮点数列表。每个浮点数代表与单个完成对应的奖励。
官方给出了一下几个使用示例:
示例 1:奖励较长的completions
以下是奖励较长完成度的标准格式的奖励函数示例:
def reward_func(completions, **kwargs):
"""奖励功能:输出的completions越长,得分越高。"""
return [float(len(completion)) for completion in completions]可以按如下方式对其进行测试:
prompts = ["The sky is", "The sun is"]
completions = [" blue.", " in the sky."]
print(reward_func(prompts=prompts, completions=completions))示例 2:具有特定格式的奖励完成
下面是一个奖励函数示例,该函数检查完成是否具有特定格式。此示例的灵感来自论文 DeepSeek-R1 中使用的格式奖励函数。它专为对话格式而设计,其中提示和完成由结构化消息组成。
import re
def format_reward_func(completions, **kwargs):
"""奖励函数:检查完成是否具有特定格式"""
pattern = r"^<think>.*?</think><answer>.*?</answer>$"
completion_contents = [completion[0]["content"] for completion in completions]
matches = [re.match(pattern, content) for content in completion_contents]
return [1.0 if match else 0.0 for match in matches]可以按如下方式测试此函数:
prompts = [
[{"role": "assistant", "content": "What is the result of (1 + 2) * 4?"}],
[{"role": "assistant", "content": "What is the result of (3 + 1) * 2?"}],
]
completions = [
[{"role": "assistant", "content": "<think>The sum of 1 and 2 is 3, which we multiply by 4 to get 12.</think><answer>(1 + 2) * 4 = 12</answer>"}],
[{"role": "assistant", "content": "The sum of 3 and 1 is 4, which we multiply by 2 to get 8. So (3 + 1) * 2 = 8."}],
]
format_reward_func(prompts=prompts, completions=completions)示例 3:基于引用的奖励完成
下面是一个 reward 函数的示例,用于检查 the 是否正确。这个例子的灵感来自论文 DeepSeek-R1 中使用的准确率奖励函数。此示例专为标准格式设计,其中数据集包含名为 ground_truth 的列。
import re
def reward_func(completions, ground_truth, **kwargs):
# Regular expression to capture content inside \boxed{}
matches = [re.search(r"\\boxed\{(.*?)\}", completion) for completion in completions]
contents = [match.group(1) if match else "" for match in matches]
# Reward 1 if the content is the same as the ground truth, 0 otherwise
return [1.0 if c == gt else 0.0 for c, gt in zip(contents, ground_truth)]可以按如下方式测试此函数:
prompts = ["Problem: Solve the equation $2x + 3 = 7$. Solution:", "Problem: Solve the equation $3x - 5 = 10$."]
completions = [r" The solution is \boxed{2}.", r" The solution is \boxed{6}."]
ground_truth = ["2", "5"]
reward_func(prompts=prompts, completions=completions, ground_truth=ground_truth)将 reward 函数传递给 trainer
要使用自定义奖励函数,请将其传递给 GRPOTrainer,如下所示:
from trl import GRPOTrainer
trainer = GRPOTrainer(
reward_funcs=reward_func, # 自定义奖励函数reward_func
...,
)如果有多个奖励函数,则可以将它们作为列表传递:
from trl import GRPOTrainer
trainer = GRPOTrainer(
reward_funcs=[reward_func1, reward_func2], # 将奖励函数写为列表形式
...,
)奖励将计算为每个函数的奖励之和。请注意,GRPOTrainer 支持多种不同类型的奖励函数。有关更多详细信息,请参阅 parameters documentation 。

