
DeepSeek-R1是在DeepSeek V3的基础上进行的,在实际效果上有了深度思考的能力,大大提高了模型的性能(对标OpenAI的O1模型),也就是对应官网上面的这个按钮?

下面来简单概述一下本文[DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning]主要的几个创新点:
- 使用纯强化学习的方式提升模型的推理能力,提出一种新的强化学习范式GRPO取代PPO。
- 提出一种新的学习流程
- 提出一种新的蒸馏模式
为何纯强化学习可以带来如此卓越的性能?
主流大模型经典训练流程(半强化学习)
在了解这个问题之前,需要知道的是前人是如何训练大语言模型的,下面是ChatGPT(不包括新的O1模型)的经典学习步骤(半强化学习):
- 首先预训练一个模型去预测输出的下一个词,得到一个具有基础知识的模型。【比如说input“我是”—>预测output“人类”】
- 然后使用SFT(监督微调)微调基础模型,让大模型学习具备对话的能力。
- 最后使用强化学习的思想,根据人类偏好,训练一个奖励模型,利用PPO算法和奖励模型微调大模型吗,使大模型学习到人类的偏好。
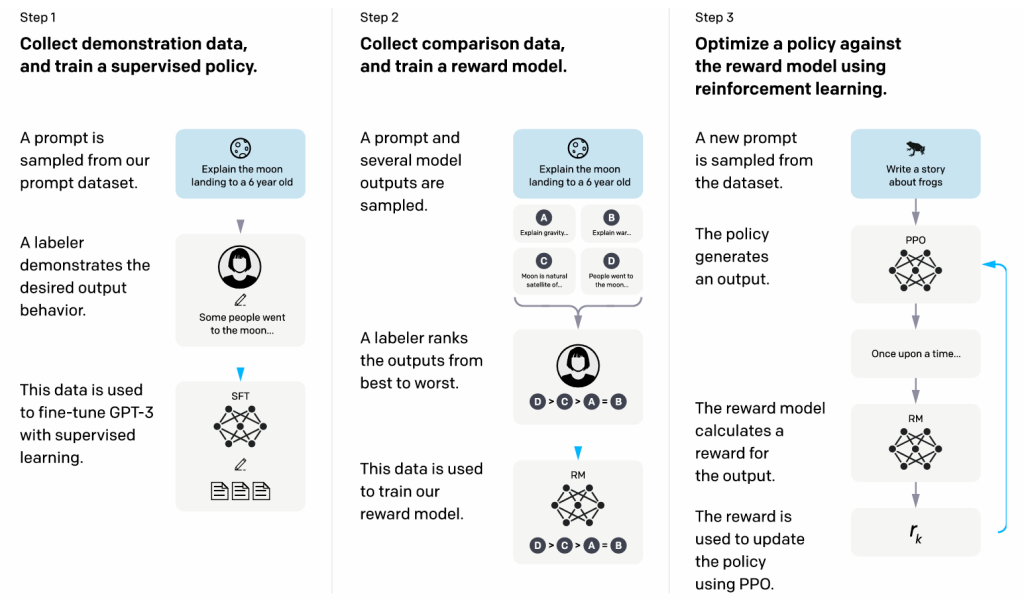
上图是2022年3月,OpenAI发表论文:Training language models to follow instructions with human feedback(遵循人类反馈指令来训练语言模型)中对上述后两步的详解。该方法的三个步骤的图表:(1)监督微调(SFT),(2)训练奖励模型(RM),(3)通过该奖励模型上的近端策略优化(PPO)进行强化学习。蓝色箭头表示该数据用于训练的一个模型。
而O1模型则在此基础上多了一个步骤:
- 使用PRM等技术,评价思维链,实现推理阶段的Scaling law。
以上便是ChatGPT、Llama等目前主流大模型的经典训练步骤。
为何最后一步必须要用到强化学习思想?
如果只看以上的学习流程,也许会发现为何一定需要第三步训练一个奖励模型去进行强化学习呢?既然数据量足够大,完全可以只用前两步简单粗暴地训练出模型。这就需要了解SFT的一个限制,也就是SFT无法提供负反馈,并且这样训练出来的模型不具备“向后看”的能力。
也就是说如果只按照上面两步的方式去训练模型的话,模型是不具备深度思考的推理能力的。举个例子?
input:ABCDEFG — > output:AAA
比如我们的数据集中有上述输入和输出,也就是我们告诉模型看到ABCDEFG这样的字符串,就输出AAA可以得到奖励,但是我们没有告诉模型如果看到BCDEFG这样的字符串,输出AAA是会扣分的,因此我们在提高输入ABCDEFG,输出AAA的概率的同时也顺带提高了输入BCDEFG,输出AAA的概率。
再举个例子说明为什么不靠强化学习会使模型不具备“向后看”的能力?
数据集中的某条数据提到 —> “上海是中国的首都,这句话是错误的”
对于模型来说,它得到的信息就会是:input:“上海是中国的” —> output:“首都”
当然也不是说这样训练出来的模型一定有问题,一定会使模型出现“幻觉”。只要数据的量足够多,还是可以一定程度上缓解这个问题的,那上面的例子来说,比如数据集中另有一条数据提到,“上海是中国的直辖市”,那么就可以解决上面的这个问题。不过话又说回来,如果真是如此小小的问题都可能引发模型出现幻觉,那么训练模型的时候对数据集的要求是巨大的。
总结来说,SFT只能教会模型如何做正确的事,但是没有考虑每条样本对整理的综合影响【微观】。而强化学习的思想其实反馈粒度是整个文本,因此强化学习更加考虑整体的影响【宏观】。
强化学习的几个方法
目前大模型主要用到的强化学习方法主要有:PPO、DPO和GRPO。
- PPO是ChatGPT使用的方法,理论上来说是有最好效果的。
- DPO是Llama使用的方法,理论上来说速度是最快的。
- GRPO是DeepSeek使用的方法,理论上来说是最便宜的。
不过以上三个方法核心思想都是一样的:提高获得高奖励token的概率,降低获得低奖励token的概率。
而三个方法实施上的不同点主要体现在奖励权重和数据采样上面。
DeepSeek-R1-Zero
DeepSeek-R1-Zero是DeepSeek-AI提出的具有实验性质的模型,主要的目的是技术方面的探索。
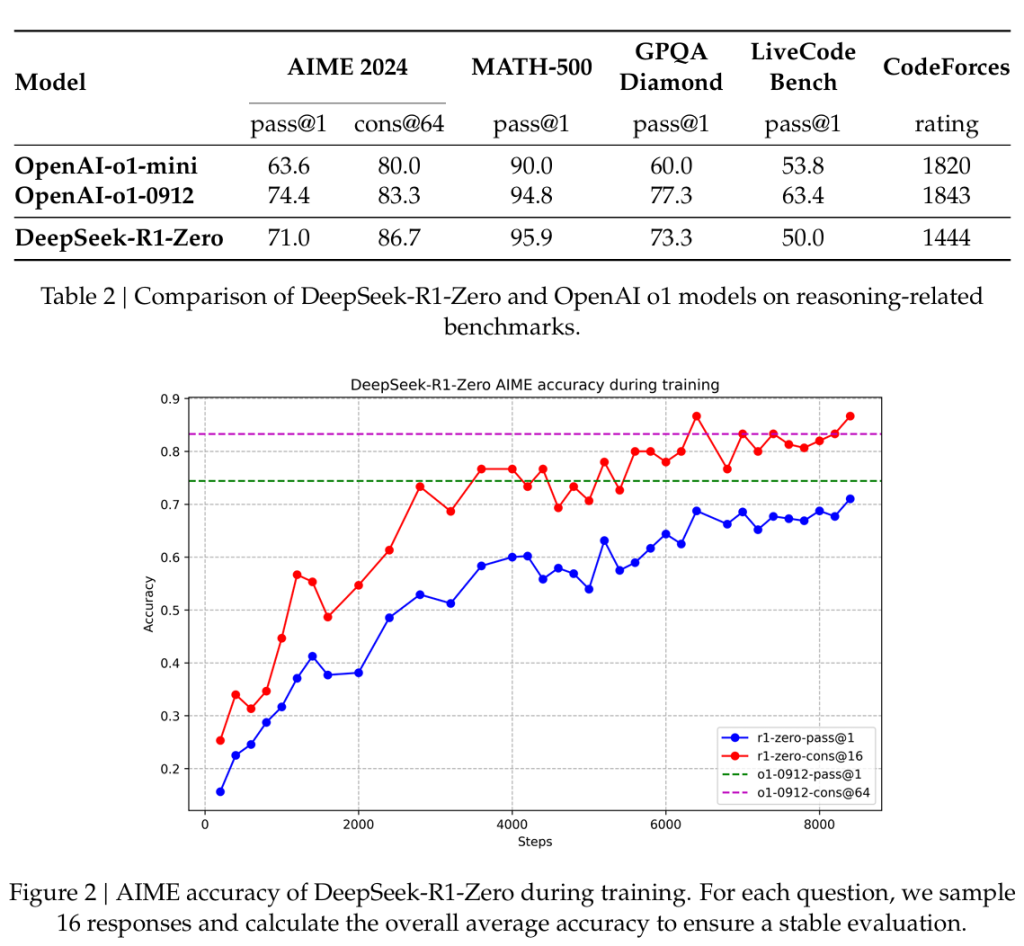
- DeepSeek-R1-Zero:这是首个通过纯强化学习(RL)训练而无需监督微调(SFT)即可显著提升推理能力的模型。它在训练过程中自然地涌现出多种强大的推理行为,例如自验证、反思和生成长链推理过程(Chain-of-Thought, CoT)。模型在AIME 2024等推理基准测试中表现出色,pass@1分数从15.6%提升至71.0%,接近OpenAI的o1-0912模型性能。
- 自进化过程:DeepSeek-R1-Zero在训练过程中展示了显著的自进化能力,随着RL训练的进行,模型逐渐学会分配更多思考时间来解决复杂问题,并自发地发展出诸如反思和探索多种解题方法等高级行为。
强化学习的奖励方法
下面将对比强化学习的两种训练时候的奖励方法,以此说明DeepSeek-R1-Zero的优越性。
之前主流的大模型如ChatGPT、Llama等模型,都是面向过程的奖励,也就是每个步骤step都对应一个奖励(PRM)。这样做可以保证每一步都进行精确校正和优化,但是这样做的坏处就是每一步都需要数据的标注,这样就会有巨大的成本,存在Reward hacking(奖励作弊)。
而DeepSeek-R1-Zero使用的是面现象结果的奖励(ORM)。这样做的好处就是只需要标注最终正确结果,标注起来比较简单,但是缺点是过程中的奖励稀疏,可能因为中间过程的出错导致结果有误。
Proximal Policy Optimization(PPO算法)
依旧还是无法绕开强化学习的具体内容,但是强化学习与深度学习并列是一门博大精深的科目,并且强化学习需要极强的数学功底,作为渣渣的我自然是无法微微详细道来,因此我准备借助AI的力量简单学习了解PPO,Proximal Policy Optimization Algorithms是OpenAI在2017年发表的同名文章中提出的。
首先PPO提出的目的是改善深度强化学习中的策略优化问题。PPO的提出是为了解决传统策略优化方法(如TRPO)在实际应用中的一些问题,如计算成本过高、对超参数的敏感性较强等。
PPO的核心思想是通过限制策略更新的幅度,避免在每次迭代中进行过大或过小的更新。
PPO的目标函数设计
PPO通过使用剪切的目标函数来约束策略的更新,使得更新后的策略不会偏离原策略太远。目标函数形式如下:
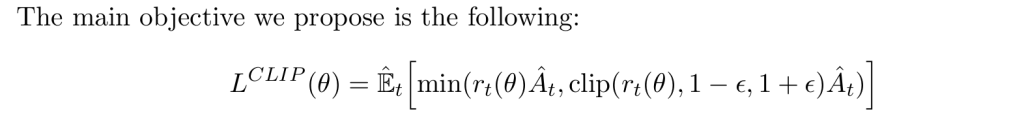
其中rt(θ)是当前策略和旧策略的概率比率,计算方式是:
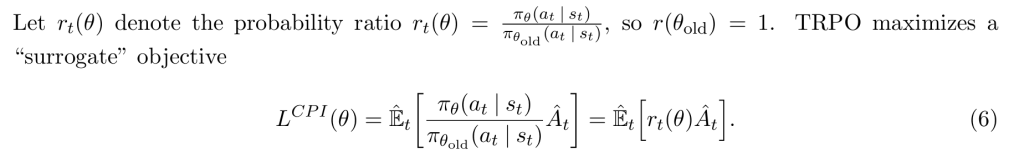
A^t是优势函数(advantage function),表示某个动作相对于某种基准动作的优势。
ϵ是一个超参数,用于控制策略更新的范围。
PPO的剪切机制
通过对rt(θ)进行剪切,PPO限制了每次策略更新的幅度。如果rt(θ)超过了 1±ϵ 的范围,算法将选择不超过这个范围的更新值。这种方法可以有效避免过大的策略更新导致策略崩溃,同时也避免了过于保守的更新。
优势函数
PPO利用优势函数来指导策略的优化。优势函数的目的是评估当前状态下采取某个动作的好坏,衡量当前动作与基准动作(通常是当前策略的动作)相比的优势。
PPO算法的优点
PPO的一个优点是相对简单,它不像TRPO那样需要计算复杂的自然梯度,因此在实际应用中,PPO通常能够更高效地进行训练。
PPO是一种近端策略优化方法,因此能够在训练过程中保持相对稳定的性能,避免了传统强化学习方法中的剧烈波动。此外,PPO通常能在多个领域中表现出色,尤其是在基于策略梯度的深度强化学习任务中,如游戏、机器人控制等。
Group Relative Policy Optimization(GRPO)
GRPO就是DeepSeek团队在2024年在DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models文章中提出的基于PPO基础上的强化学习方法。
GRPO与PPO的对比
因为本人未曾涉及强化学习的内容,这一部分的理解属实困难,这里直接借用知乎大佬@知行者的观点。
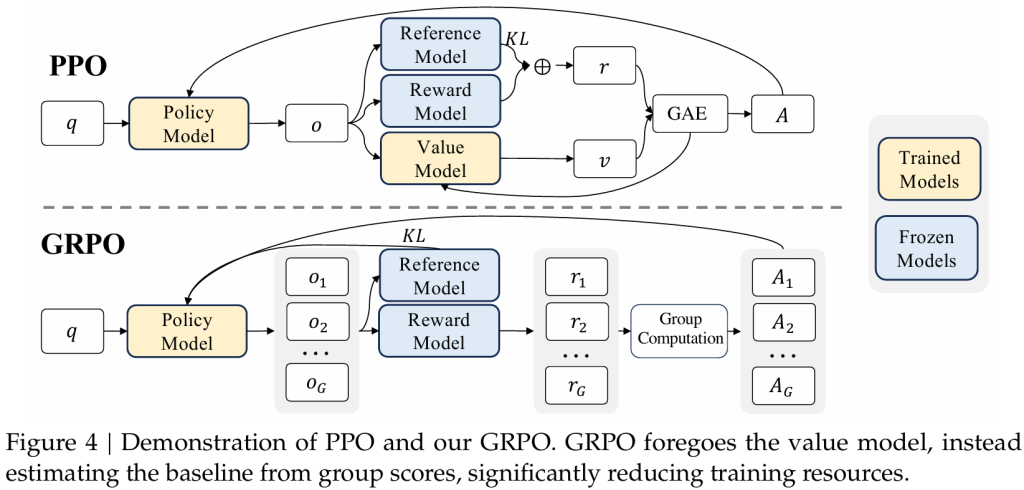
GRPO 与PPO 的主要区别有:
- GRPO省略了Value Model.
- GRPO reward计算,改成了一个q生成多个r, 然后reward 打分。
- PPO优势函数计算时,KL 是包含在GAE内部的。 GRPO 直接挪到了外面,同时修改了计算方法。
GRPO的优化
DeepSeek团队认为value function model 占用了额外的显存和计算资源。因此提出以下的改进方法。
- 去除value function, reward直接对单个q生成的response进行打分,归一化后,作为替代的优势函数。
- 同时将KL散度抑制,移到了优势函数计算的外面。KL散度的计算也进行了改进,可以见公式4. 为了保证KL散度为正值。

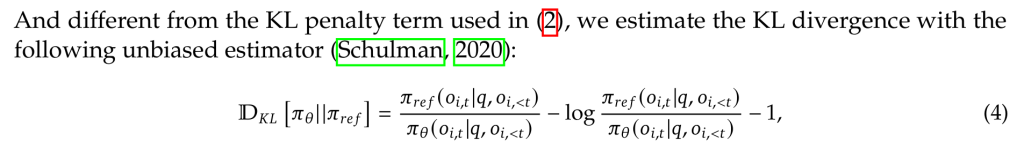
下面是基于group reward计算优势函数的归一化公式:

GRPO中的奖励模式
上图中DeepSeek团队在Reward Model中使用的为以下两种奖励:
- 准确性奖励(Accuracy Reward):检查模型最终输出的答案是否正确
- 格式奖励(Fromat Rewards):CoT是否以要求的格式输出
那么这样做的难点就在于:依赖人的精心设计。但是优点就是可以很好的解决此前主流大模型中的奖励模型存在的问题,包括训练数据的收集和Reward Hacking。
GRPO的计算流程
GRPO的计算流程包括:
- 采样一组输出并计算每个输出的奖励。
- 对组内奖励进行归一化处理。
- 使用归一化后的奖励计算优势函数。
- 通过最大化目标函数更新策略模型。
- 迭代训练,逐步优化策略模型。
DeepSeek-R1-Zero的训练流程
DeepSeek-R1-Zero模型训练时不通过任何SFT方式,而是仅使用强化学习+规则奖励模型,就能激发模型产出带反思的长思维链。和前面说的一样,DeepSeek-R1-Zero使用的是端到端(end2end)方式,是面现象结果的奖励。对比OpenAI的O1模型(生成思维链,通过模型进行打分,或者MCTS方式进行搜索。也就是前面说的面向过程的方式),大大减少了训练的成本。
下表为DeepSeek-R1-Zero训练时的数据集格式。整体的prompt提示由sys_msg+question组成。sys_msg可以理解为我们给模型设定的角色,模型在回答的时候需要遵守的默认规则(比如设定对话的对象是猫娘之类的),question就是我们对模型提出的问题,也就是模型的输入。在前期构建完下表结构的数据集之后,DeepSeek-R1-Zero直接做强化学习,也就是直接GRPO完成了模型的训练。

下图就是DeepSeek-R1-Zero训练时候的平均回答长度图,从下面的图中可以发现一个很神奇的事情:随着训练Steps的增加,DeepSeek-R1-Zero慢慢倾向于产出更长的回答,而且还出现了反思行为。【这些都是在没有外部干预的情况下,DeepSeek-R1-Zero模型在训练过程中自我进化的结果】直觉上来讲就是回答的长度随着时间的增加而变长,也就是模型思考的更多了。
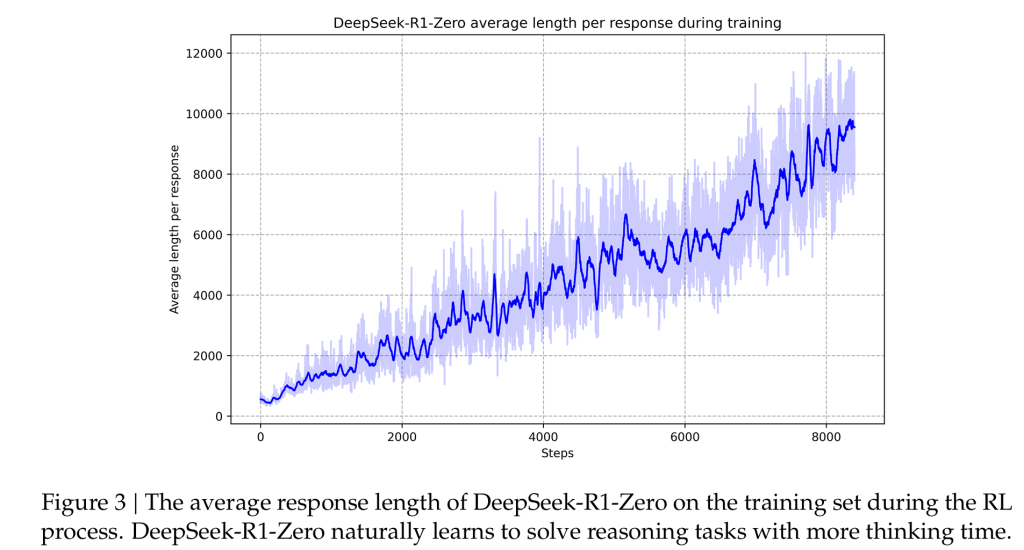
此外DeepSeek-R1-Zero的训练使用多数投票策略(例如对一条prompt采样多次,取出现次数最多的回答输出),如此便进一步增强了模型的性能。
DeepSeek-R1-Zero的成功训练证明了无需SFT,直接使用基础模型做RL,已经可以取得强大的能力。
下面的图表展示了DeepSeek-R1-Zero使用更小的成本得到了与O1对标的性能。
下表是DeepSeek-R1-Zero的问答演示,标红的部分我们可以看到,DeepSeek-R1-Zero非常重要的一点是它有思考反思的过程<think>。如前面所说,与O1对比,DeepSeek-R1-Zero的反思完全是模型自发的【无外接干扰】。

DeepSeek-R1训练流程
收到DeepSeek-R1-Zero的启发,DeepSeek团队提出了DeepSeek-R1,一套完全新的训练流程,完全颠覆了OpenAI原来提出的一套训练流程。
以下为DeepSeek-R1的训练流程:
- DeepSeek-R1的训练基于DeepSeek V3的基础之上。
- 阶段一
- 冷启动:使用少量的数据(格式如前文所说<问题, 推理轨迹CoT, 答案>)监督微调(SFT)DeepSeek V3,形成千量级的长思维链,使其具备初步的深度思考能力和规范输出格式。
- 对reason能力进行强化学习post-training(GRPO)。
- 阶段二
- 使用阶段一得到的具备一定能力的模型生成规范格式的数据(<问题, 推理轨迹CoT, 答案>)+non-reason data(非推理数据【无标准答案】)【采用拒绝采样的方式来筛选数据】,再次进行SFT,提升模型通用能力。
- 再次强化训练(GRPO),增强模型的推理能力。
流程中具体数据的格式可以看DeepSeek-R1的原文。
通过上面的训练流程来看,DeepSeek-R1的训练中再次再用了SFT方法,也就是说DeepSeek-R1-Zero证明了大模型无需SFT也能有较好的效果,但是如果使用SFT当然更好。
模型蒸馏
最后是DeepSeek团队提出的一种新的蒸馏方式。这里先来简单解释一下什么是蒸馏,直观上来说可以理解为一种”穷人的方法“,就是比如说我们手上的数据量很少,如何使我们的模型达到通义千问或者Llama这样大模型的性能呢?就是使用这些大模型生成的数据去训练我们手上的小模型,这样最终得到的模型性能理论上来说就可以非常接近被蒸馏的模型。
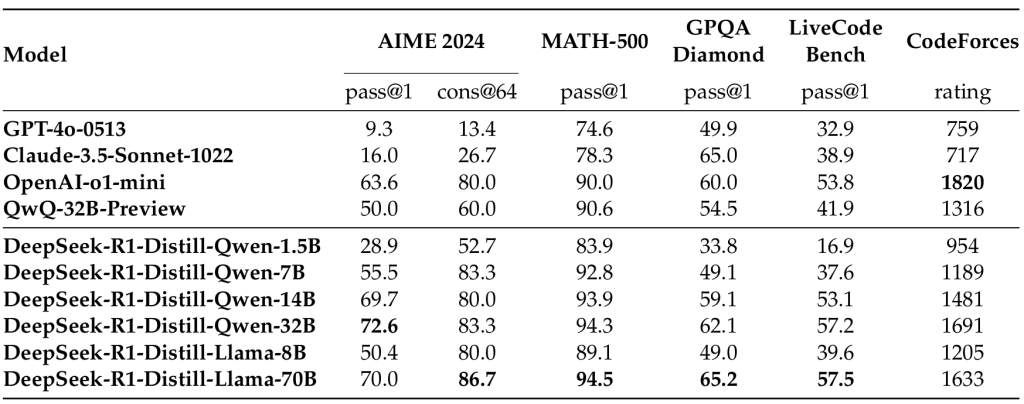
首先团队使用DeepSeek-R1生成数据对小模型SFT,结果发现这样可以显著提高小模型的推理性能。这也就意味着原先大众所以认为的小模型性能差,很大程度上不是因为训练参数少,对其影响更大的其实是训练的方式【可能模型小模型是有潜力的,但是不好训练,需要一个”好老师“大模型来进行蒸馏】,如此便是DeepSeek-R1一个非常重要的贡献,对小AI公司是极大的福音。直观上来说:硬训练一个高成本的小模型的效果远远不如蒸馏已经训练好的大模型的效果。
Reference
本文参考资料:
【AI大模型与强化学习】大模型DeepSeek R1训练全流程流程详解!GRPO算法原理详解;强化学习赋能大模型本质是什么!大模型课程 大模型蒸馏 人工智能课程_哔哩哔哩_bilibili
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
一文读懂ChatGPT的前世今生(文末附相关论文下载) – 知乎
Training language models to follow instructions with human feedback
Proximal Policy Optimization Algorithms
GRPO:Group Relative Policy Optimization – 知乎
PPO: Proximal Policy Optimization Algorithms – 知乎
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models

