【RobustSAM: Segment Anything Robustly on Degraded Images】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。

(2024.6.13 臺灣大學National Taiwan University)文章地址:https://arxiv.org/abs/2406.09627
概述
SAM生成的分割掩码的质量会受到图像的质量退化(比如低照度、噪声、模糊、恶劣天气和压缩伪影等等)的影响。
一个直观的方法是利用现有的图像恢复技术在将图像输入到SAM之前进行预处理。虽然这些方法可以在一定程度上提高图像质量,但无法保证所选的图像恢复技术能够提高图像分割的效果。这是因为大多数图像恢复算法是为了人类视觉感知而优化的,因此其并不能很好地让SAM模型进行分割。
另一种方法是用大量模糊图像对SAM模型进行训练微调。但是这样可能会影响模型在零样本任务上的泛化能力。盲目地用退化图像对SAM进行微调可能导致灾难性遗忘,即网络无意中丧失从原始清晰图像中学到的知识。
对此文章引入了RobustSAM。其在SAM的基础上新增加了两个模块:抗退化token生成模块(Anti-Degradation Token Generation Module)和抗退化掩码特征生成模块(Anti-Degradation Mask Feature Generation Module)。并且对SAM的原始输出token做了微调,使其适应该方法。在训练的过程中冻结SAM的原始模块,这样子既保证了模型处理退化图像的能力,也保证了模型的零样本任务的泛化能力。
文章构建了Robust-Seg数据集,这是一个688K不同退化的图像掩码对的集合。希望Robust-Seg能够为退化图像的分割模型建立一个新的基准。
退化图像处理的问题
自动驾驶和监控分析领域中,在处理退化图像时,基于CNN的分割模型性能会下降。
在图像恢复领域的处理方法中,将卷积神经网络应用于图像质量的增强,针对单一退化类型的方法有SRCNN、超分辨率(SR)、去噪、去雾、去训练、水下增强和去模糊等。MPRNet和HINet等尝试通过单个网络解决多重降级问题。还有最近基于Transformer的All-inOne、IPT和AirNet等多退化方法提供了更大的灵活性和更高的性能。
但是这些图像恢复的目标都是提高人类感知的视觉质量,而不是提高分割等下游任务的性能。所以这些方法应用在SAM模型中分割的效果都不好。
RobustSAM简述
对此文章提出了一种新的方法,RobustSAM,它在保留SAM的零样本学习能力的同时解决了图像退化问题。
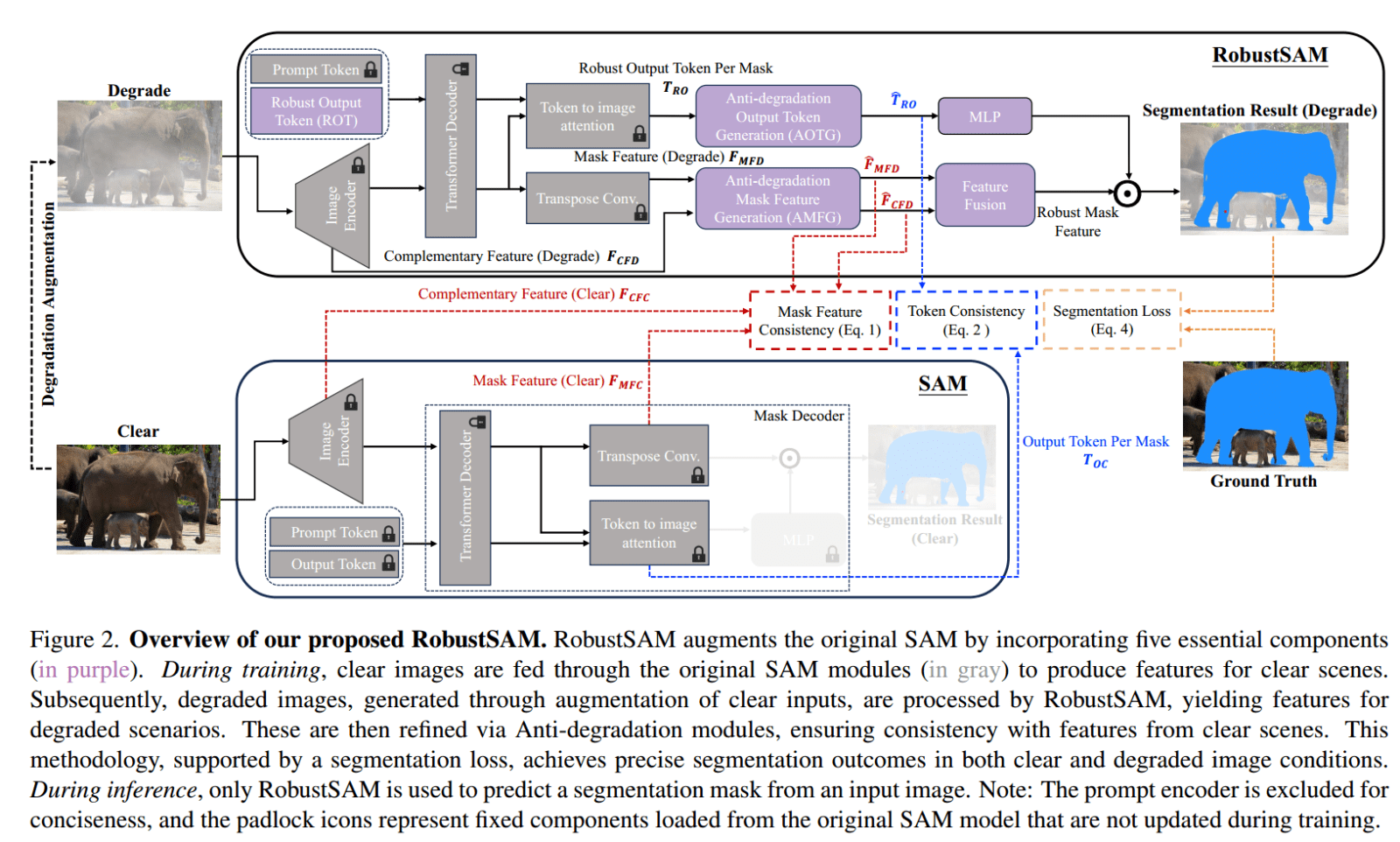
抗退化输出token生成模块 (Anti-Degradation Token Generation)
抗退化输出token生成模块 (Anti-Degradation Token Generation):生成对退化不敏感的特征token。它利用了一个自注意力机制来捕捉图像中的全局信息,从而生成对图像退化具有鲁棒性的特征。
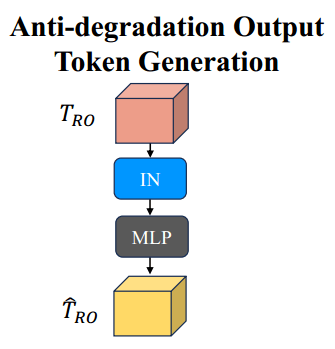
Token一致性损失:
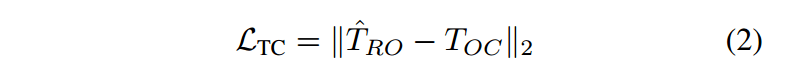
抗退化掩码特征生成模块 (Anti-Degradation Mask Feature Generation)
抗退化掩码特征生成模块 (Anti-Degradation Mask Feature Generation):生成退化不变的掩码特征。它通过一个跨注意力机制,将抗退化特征与原始 SAM 的掩码特征相结合,从而生成对退化不敏感的掩码。
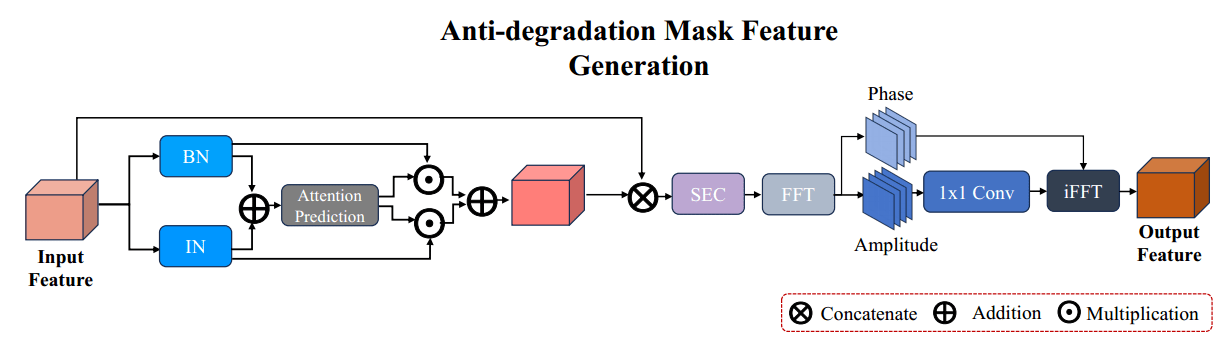
(1)输入特征首先由实例规范化(Instance Normalization, IN)处理,目的是标准化与图像退化相关的变化。
(2)实用批量归一化处理(Batch Normalization, BN)解决了由IN过程导致的潜在细节损失。
(3)为了生成对退化不敏感的特征,并确保这些特征与清晰图像条件下提取的特征保持一致,从而提高模型在各种退化条件下的分割性能,引入了傅里叶退化抑制模块(Fourier Degradation Suppression module),通过使用傅里叶变换将其从空间域转换到频域来增强集成特征。
(4)引入掩码特征一致性损失函数(Mask Feature Consistency Loss):
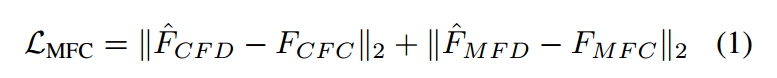
汇总计算总体损失
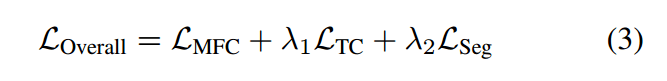
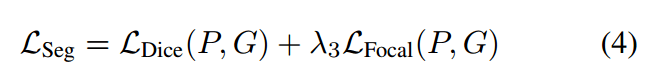
详细的训练策略
退化增强策略:将输入的训练图像进行不同类型的退化处理,比如模糊、噪声、低照度等。
一致性损失函数(Consistency Loss):在训练的过程中,模型会同时处理一对清晰图像和对应的退化图像,然后计算一致性损失。从而确保模型在处理清晰图像和退化图像时生成的特征或掩码保持一致,并且通过强制模型在不同的退化条件下输出相似的特征表示,提高模型的鲁棒性。
模型训练方面
创建了一个包含688000个图像的训练数据集Robust-Seg,其中包含多个现有的数据集(LVIS、ThinObject5k、MSRA10K、NDD20、STREETS、FSS-1000和COCO)
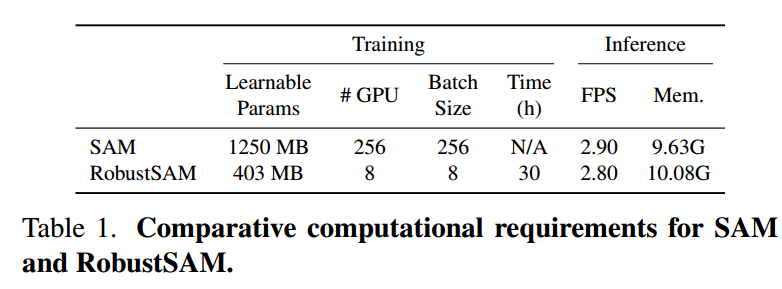
在RobustSAM的训练阶段,保持预训练的SAM参数冻结,只专注于优化所提出的模块的鲁棒性,以此来节省计算资源。
实验结果
为了评估RobustSAM的性能,采用了几个指标:交并比(IoU)、Dice系数(Dice)、像素精度(PA)和平均精度(AP)。 实验的结果:



你学的是机器学习还是深度学习?
o(////▽////)q