【Auto-Prompting SAM for Mobile Friendly 3D Medical Image Segmentation】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。


(https://arxiv.org/abs/2308.14936 2023.11.21)
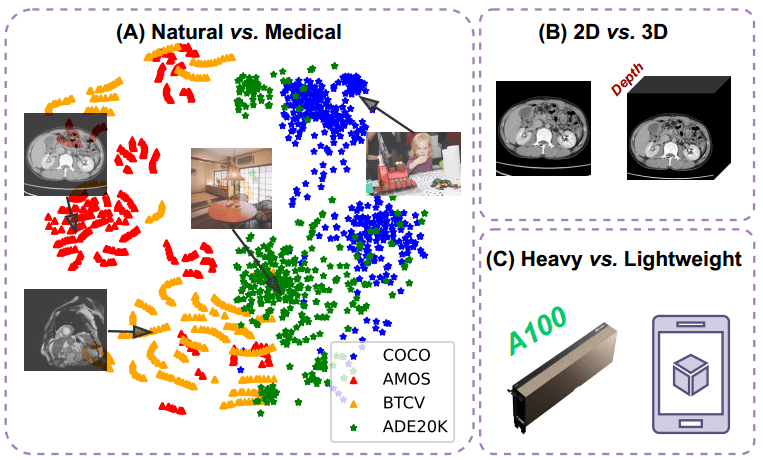
SAM模型在医学影像分割上有着较大的潜力,但是基础的SAM在常规的图像上进行训练,其训练用的数据集比较广泛,与专有领域的模型差距比较大,并且基础的SAM模型不擅长处理像CT这种3D的图像。
在开发基于SAM的医学影像分割架构需要解决几个实质性的问题:
- 自然和医学图像之间实质性领域差异的监督(oversight)(A)
- 需要有效地从3D图像中提取有用的信息(B)
- 会增加模型的计算量,即使是在推理(inference)上(C)
研究者引入了一种新的,名为AutoSAM适配器(Adapter)方法,用于将SAM从2D自然图像过渡到3D医学图像分割。
大致的操作
大致的操作如下:
最初,研究者在输入方面,对图像编码器进行了复杂的修改,使原始的2D转换器能够熟练地适应3D的输入,同时通过有效地微调参数,优化了预训练权重的可重用性。
随后,在提示编码器(prompt encoder)阶段设计了一个自动提示生成器(APG)模块,APG模块将从前一个图像编码器中提取的特征图作为输入,并自动学习后续mask encoder需要的提示。这样就省去了手动输入提示的过程。
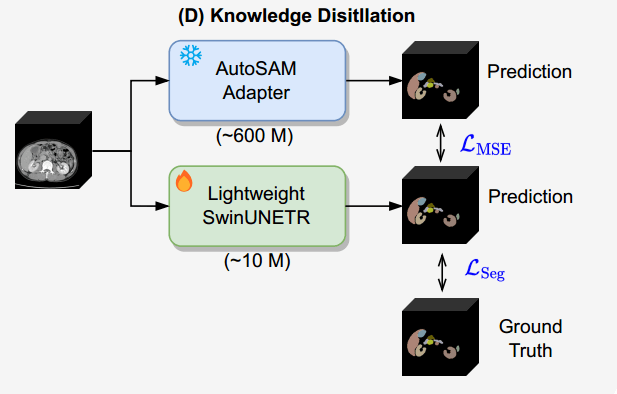
最后,可以利用知识蒸馏(KD)将从AutoSAM适配器中学习到的知识转移到其他轻量级的模型上面(如SwinUNETR等)。
先前工作
与AutoSAM适配器相关的先前工作:
SAM模型已经在超过1100万张图像的数据集上进行过了预训练,已经成为自然图像分割中的实用模型。
与SAM同期的SEEM引入了一种更全面的提示方案,以促进语义感知开放集(open-set)分割。
DINOv2专注于在数据和模型大小方面扩展ViT模型的与训练,旨在生成通用的视觉特征,从而简化下游任务的微调。
对SAM模型的架构做出的调整和改变以适应3D图像
对SAM模型的架构做出的调整和改变以适应3D图像:
AutoSAM适配器结构
尽管在2D影像方面SAM已经足够出色,但是应用在3D图像上有一些重大的问题。因为最初的SAM模型依赖于切片预测,没有考虑切片的空间背景,从而影响了模型在复杂医学领域的实用性。 为了能增强处理3D影像的能力,研究者提出了AutoSAM适配器。
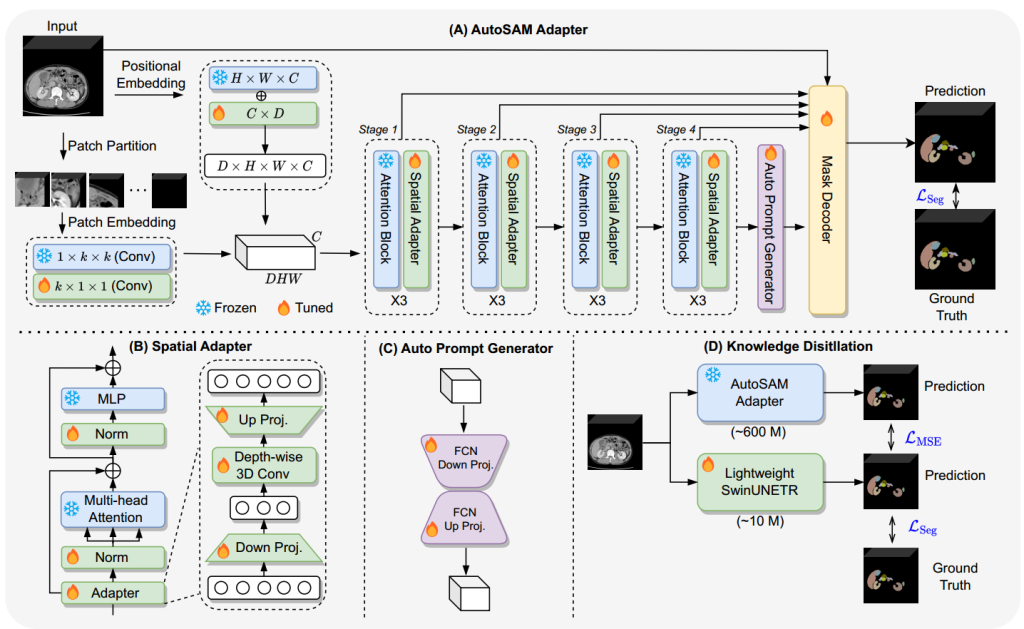
位置编码增强:增强3D图像的深度信息。通过结合预训练的二维位置编码和新增的深度编码,模型能够更好地理解三维空间中的每一个点。
Patch嵌入调整:将二维图像块(patches)的嵌入方式扩展到三维图像块。使用1×k×k和k×1×1的卷积组合来模拟三维卷积效果,从而减少参数量并提高计算效率。
Attention Block调整:适配自注意力机制以处理三维特征。通过调整queries的形状,将二维输入的大小从[B,HW,C]修改为[B,DHW,C],使其适用于三维输入,从而捕捉三维空间中的全局特征。
通过降投影和升投影层来实现特征的调整和增强。加入深度3D卷积后,适配器能够更好地捕捉三维空间中的细节,提高模型的三维空间意识。
在训练过程中,只调整卷积层、空间适配器和归一化层的参数,其余参数保持冻结状态。这种方法有助于减少训练时间和内存消耗,同时充分利用预训练模型的参数
传统的位置编码来表示提示对于3D图像来说非常耗时,图C是自动提示生成器,使用的是APG。提示部分不使用手动生成或者点和边界框,而是在最后一个注意力块和空间适配器操作之后直接获取输出特征图。自动提示生成器完全基于3D UNet,拥有轻量级结构,基于3D的卷积运算,可以轻松从头开始学习。
原本SAM的mask decoder被设计的是轻量级的,因为主要处理的是2D图像,主要使用的就是2D卷积层。在此直接将2D的卷积层换成了3D的卷积层。为了保持轻量化,研究者在decoder中加入了多层聚合机制(MLAM)。
SAM的编码器ViT部分包含了整个模型参数的很大一部分,降低ViT编码器的权重复杂程度仍然是一个很大的挑战,导致将AutoSAM适配器集成到POCT环境中变得复杂。针对这个问题,研究者利用知识蒸馏(KD)技术的有效性和医学细分特定模型的可用性,将大约有6亿个参数的AutoSAM适配器转移到具有大约一千万个参数的更小的SwinUNETR模型中。该方法旨在缩小复杂的资源密集型模型与资源感知能力更强的模型之间的差距,从而促进直接在患者所在的位置进行基于三维医学影像分割的实用诊断。
损失函数的定义
使用Dice和交叉熵损失来综合评估预测mask和真实情况之间的对齐程度。分割(segment head)的loss定义如下:
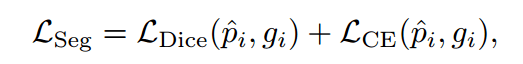
加上知识蒸馏的技术,综合计算总损失:
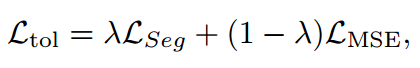
MSE的损失是轻量级学生模型和AutoSAM适配器教师模型的预定概率之间的均方误差。λ的作用是调节轻量级Swin-UNETR模型应从AutoSAM适配器生成的预测的mask和基本事实中学习多少的超参数。这样子可以将知识从AutoSAM适配器转移到SwinUNETR模型,同时在两个信息源之间取得平衡。
实验
在BTCV、AMOS、CT-ORG和一个私人机构骨盆数据集上进行评估,并且使用Dice和NSD(Normalized Surface Dice)指标进行比较。
实验结果AutoSAM Adapter普遍优于现有的SOTA方法;在BTCV数据集中,性能显著提升(Dice提升高达3%,NSD提升3%-7%);在AMOS数据集中,Dice提升高达14%,NSD提升2%-19%;在CT-ORG数据集中,取得了最高的NSD和具有竞争力的Dice得分;在私人机构骨盆数据集中,表现优越。
AutoSAM适配器的局限性
尽管AutoSAM Adapter在多器官分割任务中取得了优异的性能,但该方法也有一些局限性。例如,它没有考虑通过收集大量医学图像对图像编码器进行预训练,也没有专注于创建适用于多种不同数据集的通用模型。



好!