【HW6】Diffusion Model0.1李宏毅2021/2022春机器学习课程笔记EP18(P68-P70?)

从今天开始我将学习李宏毅教授的机器学习视频,下面是课程的连接(强推)李宏毅2021/2022春机器学习课程_哔哩哔哩_bilibili。一共有155个视频,争取都学习完成吧。
那么首先这门课程需要有一定的代码基础,简单学习一下Python的基本用法,还有里面的NumPy库等等的基本知识。再就是数学方面的基础啦,微积分、线性代数和概率论的基础都是听懂这门课必须的。
标题这里我在对应的节数(P68-P70?)上面打了问号,因为原本2021/2022的课程这里的HW6做的是用GAN去生成图像,不过我运行的是2023的作业,然后2023年用的是Diffusion Model去生成模型,所以标题上面的章节其实是不对应的。然后我也是把2023年有关于图像生成的补充提到前面来学了,笔记也是在新的2023年关于李宏毅教授的课程里面。
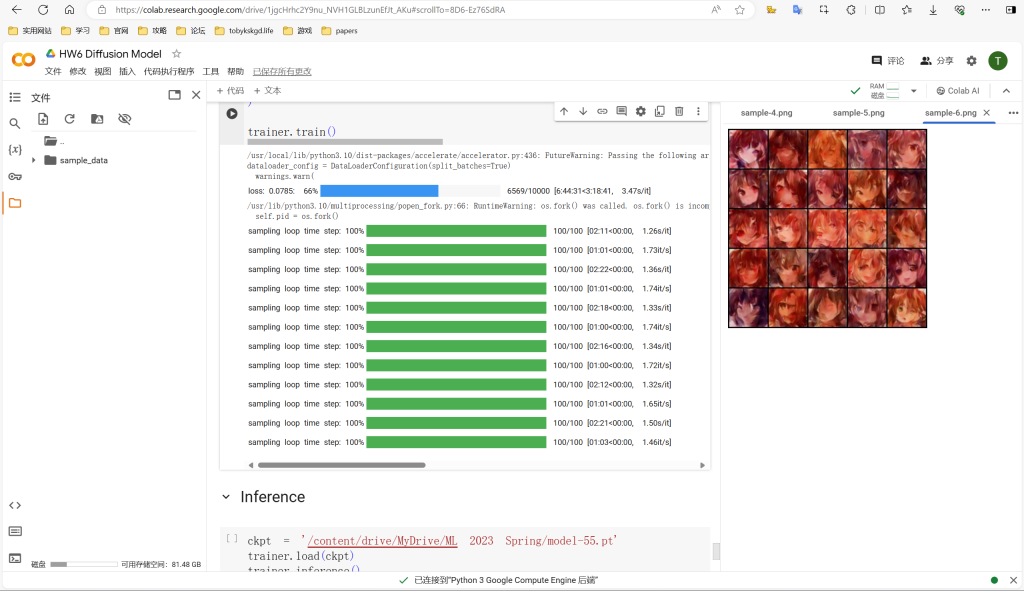
这里顺便要说的是,因为这次作业上的数据集在kaggle上面,我访问不上,于是训练用的数据集是我自己上传的,但是因为原本作业的数据集有七万多张的图片,colab一上传多的资料就会崩掉,所以这里我只上传了七百多张图片作为训练资料集,然后这个代码跑的时间也很长,66%就用了7个小时左右,所以我就在66%这里先停下来了,下面这张图片就是跑了6轮之后生成的图像:

下面是作业的代码:
expand_less
Import Packages and Set Seeds
!pip install einops
!pip install transformers
!pip install ema_pytorch
!pip install accelerateCollecting einops Downloading einops-0.7.0-py3-none-any.whl (44 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 44.6/44.6 kB 1.2 MB/s eta 0:00:00 Installing collected packages: einops Successfully installed einops-0.7.0 Requirement already satisfied: transformers in /usr/local/lib/python3.10/dist-packages (4.38.2) Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from transformers) (3.13.4) Requirement already satisfied: huggingface-hub<1.0,>=0.19.3 in /usr/local/lib/python3.10/dist-packages (from transformers) (0.20.3) Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (1.25.2) Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from transformers) (24.0) Requirement already satisfied: pyyaml>=5.1 in /usr/local/lib/python3.10/dist-packages (from transformers) (6.0.1) Requirement already satisfied: regex!=2019.12.17 in /usr/local/lib/python3.10/dist-packages (from transformers) (2023.12.25) Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from transformers) (2.31.0) Requirement already satisfied: tokenizers<0.19,>=0.14 in /usr/local/lib/python3.10/dist-packages (from transformers) (0.15.2) Requirement already satisfied: safetensors>=0.4.1 in /usr/local/lib/python3.10/dist-packages (from transformers) (0.4.2) Requirement already satisfied: tqdm>=4.27 in /usr/local/lib/python3.10/dist-packages (from transformers) (4.66.2) Requirement already satisfied: fsspec>=2023.5.0 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.19.3->transformers) (2023.6.0) Requirement already satisfied: typing-extensions>=3.7.4.3 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub<1.0,>=0.19.3->transformers) (4.11.0) Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.3.2) Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (3.6) Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2.0.7) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->transformers) (2024.2.2) Collecting ema_pytorch Downloading ema_pytorch-0.4.5-py3-none-any.whl (8.4 kB) Collecting beartype (from ema_pytorch) Downloading beartype-0.18.2-py3-none-any.whl (903 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 903.7/903.7 kB 10.0 MB/s eta 0:00:00 Requirement already satisfied: torch>=1.6 in /usr/local/lib/python3.10/dist-packages (from ema_pytorch) (2.2.1+cu121) Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch>=1.6->ema_pytorch) (3.13.4) Requirement already satisfied: typing-extensions>=4.8.0 in /usr/local/lib/python3.10/dist-packages (from torch>=1.6->ema_pytorch) (4.11.0) Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch>=1.6->ema_pytorch) (1.12) Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch>=1.6->ema_pytorch) (3.3) Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch>=1.6->ema_pytorch) (3.1.3) Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch>=1.6->ema_pytorch) (2023.6.0) Collecting nvidia-cuda-nvrtc-cu12==12.1.105 (from torch>=1.6->ema_pytorch) Using cached nvidia_cuda_nvrtc_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (23.7 MB) Collecting nvidia-cuda-runtime-cu12==12.1.105 (from torch>=1.6->ema_pytorch) Using cached nvidia_cuda_runtime_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (823 kB) Collecting nvidia-cuda-cupti-cu12==12.1.105 (from torch>=1.6->ema_pytorch) Using cached nvidia_cuda_cupti_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (14.1 MB) Collecting nvidia-cudnn-cu12==8.9.2.26 (from torch>=1.6->ema_pytorch) Using cached nvidia_cudnn_cu12-8.9.2.26-py3-none-manylinux1_x86_64.whl (731.7 MB) Collecting nvidia-cublas-cu12==12.1.3.1 (from torch>=1.6->ema_pytorch) Using cached nvidia_cublas_cu12-12.1.3.1-py3-none-manylinux1_x86_64.whl (410.6 MB) Collecting nvidia-cufft-cu12==11.0.2.54 (from torch>=1.6->ema_pytorch) Using cached nvidia_cufft_cu12-11.0.2.54-py3-none-manylinux1_x86_64.whl (121.6 MB) Collecting nvidia-curand-cu12==10.3.2.106 (from torch>=1.6->ema_pytorch) Using cached nvidia_curand_cu12-10.3.2.106-py3-none-manylinux1_x86_64.whl (56.5 MB) Collecting nvidia-cusolver-cu12==11.4.5.107 (from torch>=1.6->ema_pytorch) Using cached nvidia_cusolver_cu12-11.4.5.107-py3-none-manylinux1_x86_64.whl (124.2 MB) Collecting nvidia-cusparse-cu12==12.1.0.106 (from torch>=1.6->ema_pytorch) Using cached nvidia_cusparse_cu12-12.1.0.106-py3-none-manylinux1_x86_64.whl (196.0 MB) Collecting nvidia-nccl-cu12==2.19.3 (from torch>=1.6->ema_pytorch) Using cached nvidia_nccl_cu12-2.19.3-py3-none-manylinux1_x86_64.whl (166.0 MB) Collecting nvidia-nvtx-cu12==12.1.105 (from torch>=1.6->ema_pytorch) Using cached nvidia_nvtx_cu12-12.1.105-py3-none-manylinux1_x86_64.whl (99 kB) Requirement already satisfied: triton==2.2.0 in /usr/local/lib/python3.10/dist-packages (from torch>=1.6->ema_pytorch) (2.2.0) Collecting nvidia-nvjitlink-cu12 (from nvidia-cusolver-cu12==11.4.5.107->torch>=1.6->ema_pytorch) Using cached nvidia_nvjitlink_cu12-12.4.127-py3-none-manylinux2014_x86_64.whl (21.1 MB) Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch>=1.6->ema_pytorch) (2.1.5) Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch>=1.6->ema_pytorch) (1.3.0) Installing collected packages: nvidia-nvtx-cu12, nvidia-nvjitlink-cu12, nvidia-nccl-cu12, nvidia-curand-cu12, nvidia-cufft-cu12, nvidia-cuda-runtime-cu12, nvidia-cuda-nvrtc-cu12, nvidia-cuda-cupti-cu12, nvidia-cublas-cu12, beartype, nvidia-cusparse-cu12, nvidia-cudnn-cu12, nvidia-cusolver-cu12, ema_pytorch Successfully installed beartype-0.18.2 ema_pytorch-0.4.5 nvidia-cublas-cu12-12.1.3.1 nvidia-cuda-cupti-cu12-12.1.105 nvidia-cuda-nvrtc-cu12-12.1.105 nvidia-cuda-runtime-cu12-12.1.105 nvidia-cudnn-cu12-8.9.2.26 nvidia-cufft-cu12-11.0.2.54 nvidia-curand-cu12-10.3.2.106 nvidia-cusolver-cu12-11.4.5.107 nvidia-cusparse-cu12-12.1.0.106 nvidia-nccl-cu12-2.19.3 nvidia-nvjitlink-cu12-12.4.127 nvidia-nvtx-cu12-12.1.105 Collecting accelerate Downloading accelerate-0.29.2-py3-none-any.whl (297 kB) ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 297.4/297.4 kB 6.3 MB/s eta 0:00:00 Requirement already satisfied: numpy>=1.17 in /usr/local/lib/python3.10/dist-packages (from accelerate) (1.25.2) Requirement already satisfied: packaging>=20.0 in /usr/local/lib/python3.10/dist-packages (from accelerate) (24.0) Requirement already satisfied: psutil in /usr/local/lib/python3.10/dist-packages (from accelerate) (5.9.5) Requirement already satisfied: pyyaml in /usr/local/lib/python3.10/dist-packages (from accelerate) (6.0.1) Requirement already satisfied: torch>=1.10.0 in /usr/local/lib/python3.10/dist-packages (from accelerate) (2.2.1+cu121) Requirement already satisfied: huggingface-hub in /usr/local/lib/python3.10/dist-packages (from accelerate) (0.20.3) Requirement already satisfied: safetensors>=0.3.1 in /usr/local/lib/python3.10/dist-packages (from accelerate) (0.4.2) Requirement already satisfied: filelock in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (3.13.4) Requirement already satisfied: typing-extensions>=4.8.0 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (4.11.0) Requirement already satisfied: sympy in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (1.12) Requirement already satisfied: networkx in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (3.3) Requirement already satisfied: jinja2 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (3.1.3) Requirement already satisfied: fsspec in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (2023.6.0) Requirement already satisfied: nvidia-cuda-nvrtc-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (12.1.105) Requirement already satisfied: nvidia-cuda-runtime-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (12.1.105) Requirement already satisfied: nvidia-cuda-cupti-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (12.1.105) Requirement already satisfied: nvidia-cudnn-cu12==8.9.2.26 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (8.9.2.26) Requirement already satisfied: nvidia-cublas-cu12==12.1.3.1 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (12.1.3.1) Requirement already satisfied: nvidia-cufft-cu12==11.0.2.54 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (11.0.2.54) Requirement already satisfied: nvidia-curand-cu12==10.3.2.106 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (10.3.2.106) Requirement already satisfied: nvidia-cusolver-cu12==11.4.5.107 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (11.4.5.107) Requirement already satisfied: nvidia-cusparse-cu12==12.1.0.106 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (12.1.0.106) Requirement already satisfied: nvidia-nccl-cu12==2.19.3 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (2.19.3) Requirement already satisfied: nvidia-nvtx-cu12==12.1.105 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (12.1.105) Requirement already satisfied: triton==2.2.0 in /usr/local/lib/python3.10/dist-packages (from torch>=1.10.0->accelerate) (2.2.0) Requirement already satisfied: nvidia-nvjitlink-cu12 in /usr/local/lib/python3.10/dist-packages (from nvidia-cusolver-cu12==11.4.5.107->torch>=1.10.0->accelerate) (12.4.127) Requirement already satisfied: requests in /usr/local/lib/python3.10/dist-packages (from huggingface-hub->accelerate) (2.31.0) Requirement already satisfied: tqdm>=4.42.1 in /usr/local/lib/python3.10/dist-packages (from huggingface-hub->accelerate) (4.66.2) Requirement already satisfied: MarkupSafe>=2.0 in /usr/local/lib/python3.10/dist-packages (from jinja2->torch>=1.10.0->accelerate) (2.1.5) Requirement already satisfied: charset-normalizer<4,>=2 in /usr/local/lib/python3.10/dist-packages (from requests->huggingface-hub->accelerate) (3.3.2) Requirement already satisfied: idna<4,>=2.5 in /usr/local/lib/python3.10/dist-packages (from requests->huggingface-hub->accelerate) (3.6) Requirement already satisfied: urllib3<3,>=1.21.1 in /usr/local/lib/python3.10/dist-packages (from requests->huggingface-hub->accelerate) (2.0.7) Requirement already satisfied: certifi>=2017.4.17 in /usr/local/lib/python3.10/dist-packages (from requests->huggingface-hub->accelerate) (2024.2.2) Requirement already satisfied: mpmath>=0.19 in /usr/local/lib/python3.10/dist-packages (from sympy->torch>=1.10.0->accelerate) (1.3.0) Installing collected packages: accelerate Successfully installed accelerate-0.29.2
import math
import copy
from pathlib import Path
from random import random
from functools import partial
from collections import namedtuple
from multiprocessing import cpu_count
import torch
from torch import nn, einsum
import torch.nn.functional as F
from torch.utils.data import Dataset, DataLoader
from torch.optim import Adam
import torchvision
from torchvision import transforms as T, utils
from einops import rearrange, reduce, repeat
from einops.layers.torch import Rearrange
from PIL import Image
from tqdm.auto import tqdm
from ema_pytorch import EMA
from accelerate import Accelerator
import matplotlib.pyplot as plt
import os
torch.backends.cudnn.benchmark = True
torch.manual_seed(4096)
if torch.cuda.is_available():
torch.cuda.manual_seed(4096)Step 1: Forward process (Noise scheduler)
def linear_beta_schedule(timesteps):
"""
linear schedule, proposed in original ddpm paper
"""
scale = 1000 / timesteps
beta_start = scale * 0.0001
beta_end = scale * 0.02
return torch.linspace(beta_start, beta_end, timesteps, dtype = torch.float64)
def extract(a, t, x_shape):
b, *_ = t.shape
out = a.gather(-1, t)
return out.reshape(b, *((1,) * (len(x_shape) - 1)))Create dataset
class Dataset(Dataset):
def __init__(
self,
folder,
image_size
):
self.folder = folder
self.image_size = image_size
self.paths = [p for p in Path(f'{folder}').glob(f'**/*.jpg')]
#################################
## TODO: Data Augmentation ##
#################################
self.transform = T.Compose([
T.Resize(image_size),
T.ToTensor()
])
def __len__(self):
return len(self.paths)
def __getitem__(self, index):
path = self.paths[index]
img = Image.open(path)
return self.transform(img)Step 2: The backward process = U-Net
def exists(x):
return x is not None
def default(val, d):
if exists(val):
return val
return d() if callable(d) else d
def identity(t, *args, **kwargs):
return t
def cycle(dl):
while True:
for data in dl:
yield data
def has_int_squareroot(num):
return (math.sqrt(num) ** 2) == num
def num_to_groups(num, divisor):
groups = num // divisor
remainder = num % divisor
arr = [divisor] * groups
if remainder > 0:
arr.append(remainder)
return arr
# normalization functions
def normalize_to_neg_one_to_one(img):
return img * 2 - 1
def unnormalize_to_zero_to_one(t):
return (t + 1) * 0.5
# small helper modules
class Residual(nn.Module):
def __init__(self, fn):
super().__init__()
self.fn = fn
def forward(self, x, *args, **kwargs):
return self.fn(x, *args, **kwargs) + x
def Upsample(dim, dim_out = None):
return nn.Sequential(
nn.Upsample(scale_factor = 2, mode = 'nearest'),
nn.Conv2d(dim, default(dim_out, dim), 3, padding = 1)
)
def Downsample(dim, dim_out = None):
return nn.Sequential(
Rearrange('b c (h p1) (w p2) -> b (c p1 p2) h w', p1 = 2, p2 = 2),
nn.Conv2d(dim * 4, default(dim_out, dim), 1)
)
class WeightStandardizedConv2d(nn.Conv2d):
"""
https://arxiv.org/abs/1903.10520
weight standardization purportedly works synergistically with group normalization
"""
def forward(self, x):
eps = 1e-5 if x.dtype == torch.float32 else 1e-3
weight = self.weight
mean = reduce(weight, 'o ... -> o 1 1 1', 'mean')
var = reduce(weight, 'o ... -> o 1 1 1', partial(torch.var, unbiased = False))
normalized_weight = (weight - mean) * (var + eps).rsqrt()
return F.conv2d(x, normalized_weight, self.bias, self.stride, self.padding, self.dilation, self.groups)
class LayerNorm(nn.Module):
def __init__(self, dim):
super().__init__()
self.g = nn.Parameter(torch.ones(1, dim, 1, 1))
def forward(self, x):
eps = 1e-5 if x.dtype == torch.float32 else 1e-3
var = torch.var(x, dim = 1, unbiased = False, keepdim = True)
mean = torch.mean(x, dim = 1, keepdim = True)
return (x - mean) * (var + eps).rsqrt() * self.g
class PreNorm(nn.Module):
def __init__(self, dim, fn):
super().__init__()
self.fn = fn
self.norm = LayerNorm(dim)
def forward(self, x):
x = self.norm(x)
return self.fn(x)
# sinusoidal positional embeds
class SinusoidalPosEmb(nn.Module):
def __init__(self, dim):
super().__init__()
self.dim = dim
def forward(self, x):
device = x.device
half_dim = self.dim // 2
emb = math.log(10000) / (half_dim - 1)
emb = torch.exp(torch.arange(half_dim, device=device) * -emb)
emb = x[:, None] * emb[None, :]
emb = torch.cat((emb.sin(), emb.cos()), dim=-1)
return emb
class RandomOrLearnedSinusoidalPosEmb(nn.Module):
""" following @crowsonkb 's lead with random (learned optional) sinusoidal pos emb """
""" https://github.com/crowsonkb/v-diffusion-jax/blob/master/diffusion/models/danbooru_128.py#L8 """
def __init__(self, dim, is_random = False):
super().__init__()
assert (dim % 2) == 0
half_dim = dim // 2
self.weights = nn.Parameter(torch.randn(half_dim), requires_grad = not is_random)
def forward(self, x):
x = rearrange(x, 'b -> b 1')
freqs = x * rearrange(self.weights, 'd -> 1 d') * 2 * math.pi
fouriered = torch.cat((freqs.sin(), freqs.cos()), dim = -1)
fouriered = torch.cat((x, fouriered), dim = -1)
return fouriered
# building block modules
class Block(nn.Module):
def __init__(self, dim, dim_out, groups = 8):
super().__init__()
self.proj = WeightStandardizedConv2d(dim, dim_out, 3, padding = 1)
self.norm = nn.GroupNorm(groups, dim_out)
self.act = nn.SiLU()
def forward(self, x, scale_shift = None):
x = self.proj(x)
x = self.norm(x)
if exists(scale_shift):
scale, shift = scale_shift
x = x * (scale + 1) + shift
x = self.act(x)
return x
class ResnetBlock(nn.Module):
def __init__(self, dim, dim_out, *, time_emb_dim = None, groups = 8):
super().__init__()
self.mlp = nn.Sequential(
nn.SiLU(),
nn.Linear(time_emb_dim, dim_out * 2)
) if exists(time_emb_dim) else None
self.block1 = Block(dim, dim_out, groups = groups)
self.block2 = Block(dim_out, dim_out, groups = groups)
self.res_conv = nn.Conv2d(dim, dim_out, 1) if dim != dim_out else nn.Identity()
def forward(self, x, time_emb = None):
scale_shift = None
if exists(self.mlp) and exists(time_emb):
time_emb = self.mlp(time_emb)
time_emb = rearrange(time_emb, 'b c -> b c 1 1')
scale_shift = time_emb.chunk(2, dim = 1)
h = self.block1(x, scale_shift = scale_shift)
h = self.block2(h)
return h + self.res_conv(x)
class LinearAttention(nn.Module):
def __init__(self, dim, heads = 4, dim_head = 32):
super().__init__()
self.scale = dim_head ** -0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
self.to_out = nn.Sequential(
nn.Conv2d(hidden_dim, dim, 1),
LayerNorm(dim)
)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim = 1)
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> b h c (x y)', h = self.heads), qkv)
q = q.softmax(dim = -2)
k = k.softmax(dim = -1)
q = q * self.scale
v = v / (h * w)
context = torch.einsum('b h d n, b h e n -> b h d e', k, v)
out = torch.einsum('b h d e, b h d n -> b h e n', context, q)
out = rearrange(out, 'b h c (x y) -> b (h c) x y', h = self.heads, x = h, y = w)
return self.to_out(out)
class Attention(nn.Module):
def __init__(self, dim, heads = 4, dim_head = 32):
super().__init__()
self.scale = dim_head ** -0.5
self.heads = heads
hidden_dim = dim_head * heads
self.to_qkv = nn.Conv2d(dim, hidden_dim * 3, 1, bias = False)
self.to_out = nn.Conv2d(hidden_dim, dim, 1)
def forward(self, x):
b, c, h, w = x.shape
qkv = self.to_qkv(x).chunk(3, dim = 1)
q, k, v = map(lambda t: rearrange(t, 'b (h c) x y -> b h c (x y)', h = self.heads), qkv)
q = q * self.scale
sim = torch.einsum('b h d i, b h d j -> b h i j', q, k)
attn = sim.softmax(dim = -1)
out = torch.einsum('b h i j, b h d j -> b h i d', attn, v)
out = rearrange(out, 'b h (x y) d -> b (h d) x y', x = h, y = w)
return self.to_out(out)
# model
class Unet(nn.Module):
def __init__(
self,
dim,
init_dim = None,
out_dim = None,
dim_mults=(1, 2, 4, 8),
channels = 3,
resnet_block_groups = 8,
learned_sinusoidal_cond = False,
random_fourier_features = False,
learned_sinusoidal_dim = 16
):
super().__init__()
# determine dimensions
self.channels = channels
init_dim = default(init_dim, dim)
self.init_conv = nn.Conv2d(channels, init_dim, 7, padding = 3)
dims = [init_dim, *map(lambda m: dim * m, dim_mults)]
in_out = list(zip(dims[:-1], dims[1:]))
block_klass = partial(ResnetBlock, groups = resnet_block_groups)
# time embeddings
time_dim = dim * 4
self.random_or_learned_sinusoidal_cond = learned_sinusoidal_cond or random_fourier_features
if self.random_or_learned_sinusoidal_cond:
sinu_pos_emb = RandomOrLearnedSinusoidalPosEmb(learned_sinusoidal_dim, random_fourier_features)
fourier_dim = learned_sinusoidal_dim + 1
else:
sinu_pos_emb = SinusoidalPosEmb(dim)
fourier_dim = dim
self.time_mlp = nn.Sequential(
sinu_pos_emb,
nn.Linear(fourier_dim, time_dim),
nn.GELU(),
nn.Linear(time_dim, time_dim)
)
# layers
self.downs = nn.ModuleList([])
self.ups = nn.ModuleList([])
num_resolutions = len(in_out)
for ind, (dim_in, dim_out) in enumerate(in_out):
is_last = ind >= (num_resolutions - 1)
self.downs.append(nn.ModuleList([
block_klass(dim_in, dim_in, time_emb_dim = time_dim),
block_klass(dim_in, dim_in, time_emb_dim = time_dim),
Residual(PreNorm(dim_in, LinearAttention(dim_in))),
Downsample(dim_in, dim_out) if not is_last else nn.Conv2d(dim_in, dim_out, 3, padding = 1)
]))
mid_dim = dims[-1]
self.mid_block1 = block_klass(mid_dim, mid_dim, time_emb_dim = time_dim)
self.mid_attn = Residual(PreNorm(mid_dim, Attention(mid_dim)))
self.mid_block2 = block_klass(mid_dim, mid_dim, time_emb_dim = time_dim)
for ind, (dim_in, dim_out) in enumerate(reversed(in_out)):
is_last = ind == (len(in_out) - 1)
self.ups.append(nn.ModuleList([
block_klass(dim_out + dim_in, dim_out, time_emb_dim = time_dim),
block_klass(dim_out + dim_in, dim_out, time_emb_dim = time_dim),
Residual(PreNorm(dim_out, LinearAttention(dim_out))),
Upsample(dim_out, dim_in) if not is_last else nn.Conv2d(dim_out, dim_in, 3, padding = 1)
]))
self.out_dim = default(out_dim, channels)
self.final_res_block = block_klass(dim * 2, dim, time_emb_dim = time_dim)
self.final_conv = nn.Conv2d(dim, self.out_dim, 1)
def forward(self, x, time):
x = self.init_conv(x)
r = x.clone()
t = self.time_mlp(time)
h = []
for block1, block2, attn, downsample in self.downs:
x = block1(x, t)
h.append(x)
x = block2(x, t)
x = attn(x)
h.append(x)
x = downsample(x)
x = self.mid_block1(x, t)
x = self.mid_attn(x)
x = self.mid_block2(x, t)
for block1, block2, attn, upsample in self.ups:
x = torch.cat((x, h.pop()), dim = 1)
x = block1(x, t)
x = torch.cat((x, h.pop()), dim = 1)
x = block2(x, t)
x = attn(x)
x = upsample(x)
x = torch.cat((x, r), dim = 1)
x = self.final_res_block(x, t)
return self.final_conv(x)
model = Unet(64)Step 3: The Diffusion Process
Define diffusion process, including generating noisy models, sample…
class GaussianDiffusion(nn.Module):
def __init__(
self,
model,
*,
image_size,
timesteps = 1000,
beta_schedule = 'linear',
auto_normalize = True
):
super().__init__()
assert not (type(self) == GaussianDiffusion and model.channels != model.out_dim)
assert not model.random_or_learned_sinusoidal_cond
self.model = model
self.channels = self.model.channels
self.image_size = image_size
if beta_schedule == 'linear':
beta_schedule_fn = linear_beta_schedule
else:
raise ValueError(f'unknown beta schedule {beta_schedule}')
# calculate beta and other precalculated parameters
betas = beta_schedule_fn(timesteps)
alphas = 1. - betas
alphas_cumprod = torch.cumprod(alphas, dim=0)
alphas_cumprod_prev = F.pad(alphas_cumprod[:-1], (1, 0), value = 1.)
timesteps, = betas.shape
self.num_timesteps = int(timesteps)
# sampling related parameters
self.sampling_timesteps = timesteps # default num sampling timesteps to number of timesteps at training
# helper function to register buffer from float64 to float32
register_buffer = lambda name, val: self.register_buffer(name, val.to(torch.float32))
register_buffer('betas', betas)
register_buffer('alphas_cumprod', alphas_cumprod)
register_buffer('alphas_cumprod_prev', alphas_cumprod_prev)
# calculations for diffusion q(x_t | x_{t-1}) and others
register_buffer('sqrt_alphas_cumprod', torch.sqrt(alphas_cumprod))
register_buffer('sqrt_one_minus_alphas_cumprod', torch.sqrt(1. - alphas_cumprod))
register_buffer('log_one_minus_alphas_cumprod', torch.log(1. - alphas_cumprod))
register_buffer('sqrt_recip_alphas_cumprod', torch.sqrt(1. / alphas_cumprod))
register_buffer('sqrt_recipm1_alphas_cumprod', torch.sqrt(1. / alphas_cumprod - 1))
# calculations for posterior q(x_{t-1} | x_t, x_0)
posterior_variance = betas * (1. - alphas_cumprod_prev) / (1. - alphas_cumprod)
# above: equal to 1. / (1. / (1. - alpha_cumprod_tm1) + alpha_t / beta_t)
register_buffer('posterior_variance', posterior_variance)
# below: log calculation clipped because the posterior variance is 0 at the beginning of the diffusion chain
register_buffer('posterior_log_variance_clipped', torch.log(posterior_variance.clamp(min =1e-20)))
register_buffer('posterior_mean_coef1', betas * torch.sqrt(alphas_cumprod_prev) / (1. - alphas_cumprod))
register_buffer('posterior_mean_coef2', (1. - alphas_cumprod_prev) * torch.sqrt(alphas) / (1. - alphas_cumprod))
# derive loss weight
# snr - signal noise ratio
snr = alphas_cumprod / (1 - alphas_cumprod)
# https://arxiv.org/abs/2303.09556
maybe_clipped_snr = snr.clone()
register_buffer('loss_weight', maybe_clipped_snr / snr)
# auto-normalization of data [0, 1] -> [-1, 1] - can turn off by setting it to be False
self.normalize = normalize_to_neg_one_to_one if auto_normalize else identity
self.unnormalize = unnormalize_to_zero_to_one if auto_normalize else identity
def predict_start_from_noise(self, x_t, t, noise):
return (
extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t -
extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape) * noise
)
def predict_noise_from_start(self, x_t, t, x0):
return (
(extract(self.sqrt_recip_alphas_cumprod, t, x_t.shape) * x_t - x0) / \
extract(self.sqrt_recipm1_alphas_cumprod, t, x_t.shape)
)
def q_posterior(self, x_start, x_t, t):
posterior_mean = (
extract(self.posterior_mean_coef1, t, x_t.shape) * x_start +
extract(self.posterior_mean_coef2, t, x_t.shape) * x_t
)
posterior_variance = extract(self.posterior_variance, t, x_t.shape)
posterior_log_variance_clipped = extract(self.posterior_log_variance_clipped, t, x_t.shape)
return posterior_mean, posterior_variance, posterior_log_variance_clipped
def model_predictions(self, x, t, clip_x_start = False, rederive_pred_noise = False):
model_output = self.model(x, t)
maybe_clip = partial(torch.clamp, min = -1., max = 1.) if clip_x_start else identity
pred_noise = model_output
x_start = self.predict_start_from_noise(x, t, pred_noise)
x_start = maybe_clip(x_start)
if clip_x_start and rederive_pred_noise:
pred_noise = self.predict_noise_from_start(x, t, x_start)
return pred_noise, x_start
def p_mean_variance(self, x, t, clip_denoised = True):
noise, x_start = self.model_predictions(x, t)
if clip_denoised:
x_start.clamp_(-1., 1.)
model_mean, posterior_variance, posterior_log_variance = self.q_posterior(x_start = x_start, x_t = x, t = t)
return model_mean, posterior_variance, posterior_log_variance, x_start
@torch.no_grad()
def p_sample(self, x, t: int):
b, *_, device = *x.shape, x.device
batched_times = torch.full((b,), t, device = x.device, dtype = torch.long)
model_mean, _, model_log_variance, x_start = self.p_mean_variance(x = x, t = batched_times, clip_denoised = True)
noise = torch.randn_like(x) if t > 0 else 0. # no noise if t == 0
pred_img = model_mean + (0.5 * model_log_variance).exp() * noise
return pred_img, x_start
@torch.no_grad()
def p_sample_loop(self, shape, return_all_timesteps = False):
batch, device = shape[0], self.betas.device
img = torch.randn(shape, device = device)
imgs = [img]
x_start = None
###########################################
## TODO: plot the sampling process ##
###########################################
for t in tqdm(reversed(range(0, self.num_timesteps)), desc = 'sampling loop time step', total = self.num_timesteps):
img, x_start = self.p_sample(img, t)
imgs.append(img)
ret = img if not return_all_timesteps else torch.stack(imgs, dim = 1)
ret = self.unnormalize(ret)
return ret
@torch.no_grad()
def sample(self, batch_size = 16, return_all_timesteps = False):
image_size, channels = self.image_size, self.channels
sample_fn = self.p_sample_loop
return sample_fn((batch_size, channels, image_size, image_size), return_all_timesteps = return_all_timesteps)
def q_sample(self, x_start, t, noise=None):
noise = default(noise, lambda: torch.randn_like(x_start))
return (
extract(self.sqrt_alphas_cumprod, t, x_start.shape) * x_start +
extract(self.sqrt_one_minus_alphas_cumprod, t, x_start.shape) * noise
)
@property
def loss_fn(self):
return F.mse_loss
def p_losses(self, x_start, t, noise = None):
b, c, h, w = x_start.shape
noise = default(noise, lambda: torch.randn_like(x_start))
# noise sample
x = self.q_sample(x_start = x_start, t = t, noise = noise)
# predict and take gradient step
model_out = self.model(x, t)
loss = self.loss_fn(model_out, noise, reduction = 'none')
loss = reduce(loss, 'b ... -> b (...)', 'mean')
loss = loss * extract(self.loss_weight, t, loss.shape)
return loss.mean()
def forward(self, img, *args, **kwargs):
b, c, h, w, device, img_size, = *img.shape, img.device, self.image_size
assert h == img_size and w == img_size, f'height and width of image must be {img_size}'
t = torch.randint(0, self.num_timesteps, (b,), device=device).long()
img = self.normalize(img)
return self.p_losses(img, t, *args, **kwargs)
Define Trainer: define the updating process
class Trainer(object):
def __init__(
self,
diffusion_model,
folder,
*,
train_batch_size = 16,
gradient_accumulate_every = 1,
train_lr = 1e-4,
train_num_steps = 100000,
ema_update_every = 10,
ema_decay = 0.995,
adam_betas = (0.9, 0.99),
save_and_sample_every = 1000,
num_samples = 25,
results_folder = './results',
split_batches = True,
inception_block_idx = 2048
):
super().__init__()
# accelerator
self.accelerator = Accelerator(
split_batches = split_batches,
mixed_precision = 'no'
)
# model
self.model = diffusion_model
self.channels = diffusion_model.channels
# sampling and training hyperparameters
assert has_int_squareroot(num_samples), 'number of samples must have an integer square root'
self.num_samples = num_samples
self.save_and_sample_every = save_and_sample_every
self.batch_size = train_batch_size
self.gradient_accumulate_every = gradient_accumulate_every
self.train_num_steps = train_num_steps
self.image_size = diffusion_model.image_size
# dataset and dataloader
self.ds = Dataset(folder, self.image_size)
dl = DataLoader(self.ds, batch_size = train_batch_size, shuffle = True, pin_memory = True, num_workers = cpu_count())
dl = self.accelerator.prepare(dl)
self.dl = cycle(dl)
# optimizer
self.opt = Adam(diffusion_model.parameters(), lr = train_lr, betas = adam_betas)
# for logging results in a folder periodically
if self.accelerator.is_main_process:
self.ema = EMA(diffusion_model, beta = ema_decay, update_every = ema_update_every)
self.ema.to(self.device)
self.results_folder = Path(results_folder)
self.results_folder.mkdir(exist_ok = True)
# step counter state
self.step = 0
# prepare model, dataloader, optimizer with accelerator
self.model, self.opt = self.accelerator.prepare(self.model, self.opt)
@property
def device(self):
return self.accelerator.device
def save(self, milestone):
if not self.accelerator.is_local_main_process:
return
data = {
'step': self.step,
'model': self.accelerator.get_state_dict(self.model),
'opt': self.opt.state_dict(),
'ema': self.ema.state_dict(),
'scaler': self.accelerator.scaler.state_dict() if exists(self.accelerator.scaler) else None,
}
torch.save(data, str(self.results_folder / f'model-{milestone}.pt'))
def load(self, ckpt):
accelerator = self.accelerator
device = accelerator.device
data = torch.load(ckpt, map_location=device)
model = self.accelerator.unwrap_model(self.model)
model.load_state_dict(data['model'])
self.step = data['step']
self.opt.load_state_dict(data['opt'])
if self.accelerator.is_main_process:
self.ema.load_state_dict(data["ema"])
if exists(self.accelerator.scaler) and exists(data['scaler']):
self.accelerator.scaler.load_state_dict(data['scaler'])
def train(self):
accelerator = self.accelerator
device = accelerator.device
with tqdm(initial = self.step, total = self.train_num_steps, disable = not accelerator.is_main_process) as pbar:
while self.step < self.train_num_steps:
total_loss = 0.
for _ in range(self.gradient_accumulate_every):
data = next(self.dl).to(device)
with self.accelerator.autocast():
loss = self.model(data)
loss = loss / self.gradient_accumulate_every
total_loss += loss.item()
self.accelerator.backward(loss)
accelerator.clip_grad_norm_(self.model.parameters(), 1.0)
pbar.set_description(f'loss: {total_loss:.4f}')
accelerator.wait_for_everyone()
self.opt.step()
self.opt.zero_grad()
accelerator.wait_for_everyone()
self.step += 1
if accelerator.is_main_process:
self.ema.update()
if self.step != 0 and self.step % self.save_and_sample_every == 0:
self.ema.ema_model.eval()
with torch.no_grad():
milestone = self.step // self.save_and_sample_every
batches = num_to_groups(self.num_samples, self.batch_size)
all_images_list = list(map(lambda n: self.ema.ema_model.sample(batch_size=n), batches))
all_images = torch.cat(all_images_list, dim = 0)
utils.save_image(all_images, str(self.results_folder / f'sample-{milestone}.png'), nrow = int(math.sqrt(self.num_samples)))
self.save(milestone)
pbar.update(1)
accelerator.print('training complete')
def inference(self, num=1000, n_iter=5, output_path='./submission'):
if not os.path.exists(output_path):
os.mkdir(output_path)
with torch.no_grad():
for i in range(n_iter):
batches = num_to_groups(num // n_iter, 200)
all_images = list(map(lambda n: self.ema.ema_model.sample(batch_size=n), batches))[0]
for j in range(all_images.size(0)):
torchvision.utils.save_image(all_images[j], f'{output_path}/{i * 200 + j + 1}.jpg')
Training Hyper-parameters
path = '/content/faces'
IMG_SIZE = 64 # Size of images, do not change this if you do not know why you need to change
batch_size = 16
train_num_steps = 10000 # total training steps
lr = 1e-3
grad_steps = 1 # gradient accumulation steps, the equivalent batch size for updating equals to batch_size * grad_steps = 16 * 1
ema_decay = 0.995 # exponential moving average decay
channels = 16 # Numbers of channels of the first layer of CNN
dim_mults = (1, 2, 4) # The model size will be (channels, 2 * channels, 4 * channels, 4 * channels, 2 * channels, channels)
timesteps = 100 # Number of steps (adding noise)
beta_schedule = 'linear'
model = Unet(
dim = channels,
dim_mults = dim_mults
)
diffusion = GaussianDiffusion(
model,
image_size = IMG_SIZE,
timesteps = timesteps,
beta_schedule = beta_schedule
)
trainer = Trainer(
diffusion,
path,
train_batch_size = batch_size,
train_lr = lr,
train_num_steps = train_num_steps,
gradient_accumulate_every = grad_steps,
ema_decay = ema_decay,
save_and_sample_every = 1000
)
trainer.train()/usr/local/lib/python3.10/dist-packages/accelerate/accelerator.py:436: FutureWarning: Passing the following arguments to `Accelerator` is deprecated and will be removed in version 1.0 of Accelerate: dict_keys(['split_batches']). Please pass an `accelerate.DataLoaderConfiguration` instead: dataloader_config = DataLoaderConfiguration(split_batches=True) warnings.warn(
loss: 0.0785: 66%
6569/10000 [6:44:31<3:18:41, 3.47s/it]
/usr/lib/python3.10/multiprocessing/popen_fork.py:66: RuntimeWarning: os.fork() was called. os.fork() is incompatible with multithreaded code, and JAX is multithreaded, so this will likely lead to a deadlock. self.pid = os.fork()
sampling loop time step: 100%
100/100 [02:11<00:00, 1.26s/it]
sampling loop time step: 100%
100/100 [01:01<00:00, 1.73it/s]
sampling loop time step: 100%
100/100 [02:22<00:00, 1.36s/it]
sampling loop time step: 100%
100/100 [01:01<00:00, 1.74it/s]
sampling loop time step: 100%
100/100 [02:18<00:00, 1.33s/it]
sampling loop time step: 100%
100/100 [01:00<00:00, 1.74it/s]
sampling loop time step: 100%
100/100 [02:16<00:00, 1.34s/it]
sampling loop time step: 100%
100/100 [01:00<00:00, 1.72it/s]
sampling loop time step: 100%
100/100 [02:12<00:00, 1.32s/it]
sampling loop time step: 100%
100/100 [01:01<00:00, 1.65it/s]
sampling loop time step: 100%
100/100 [02:21<00:00, 1.50s/it]
sampling loop time step: 100%
100/100 [01:03<00:00, 1.46it/s]
Inference
ckpt = '/content/drive/MyDrive/ML 2023 Spring/model-55.pt'
trainer.load(ckpt)
trainer.inference()%cd ./submission
!tar -zcf ../submission.tgz *.jpg
%cd ..