【生成式对抗网络GAN(下):理论介绍与WGAN+生成器效能评估与条件生成+Cycle GAN】李宏毅2021/2022春机器学习课程笔记EP17(P59-P61)

从今天开始我将学习李宏毅教授的机器学习视频,下面是课程的连接(强推)李宏毅2021/2022春机器学习课程_哔哩哔哩_bilibili。一共有155个视频,争取都学习完成吧。
那么首先这门课程需要有一定的代码基础,简单学习一下Python的基本用法,还有里面的NumPy库等等的基本知识。再就是数学方面的基础啦,微积分、线性代数和概率论的基础都是听懂这门课必须的。
关于GAN剩下的介绍可能会比较长,下面会分三个部分来讲吧。
GAN的理论介绍与WGAN
首先是关于GAN的理论介绍与WGAN。
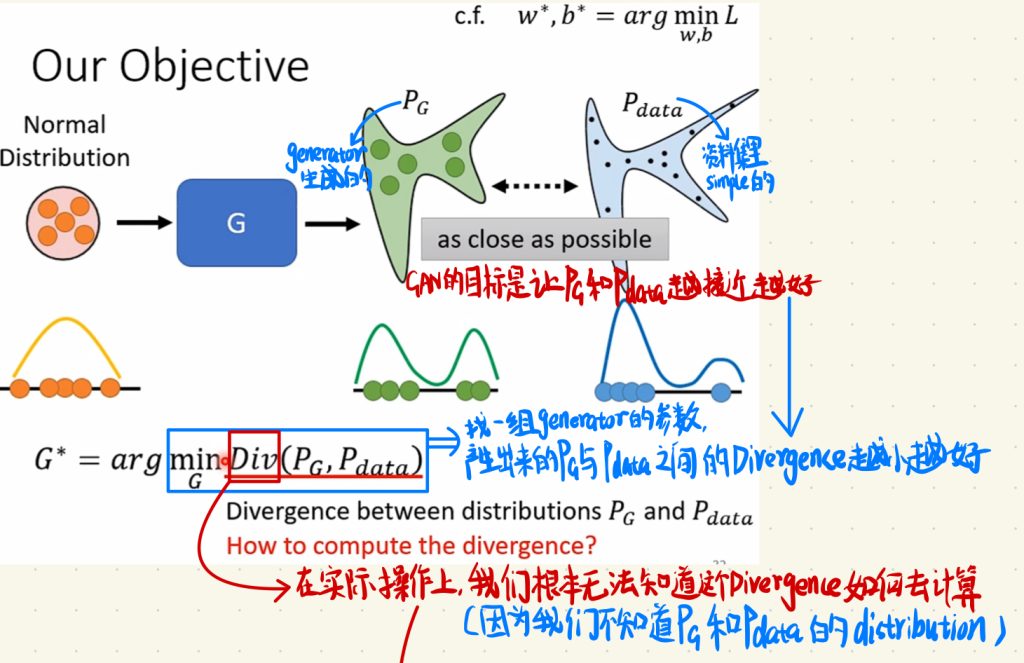
回想上一部分对于GAN的说明,首先GAN是一个生成的神经网络,我们做的是将一个Distribution放到generator里面,然后得到GAN生成出来图片的分布PG,Pdata就是我们自己准备的想让机器学到的正确的资料集。然后我们的目标是让PG跟Pdata之间越接近越好,这个目标用数学的式子来表示的话就是:
G* = argminGDiv(PG, Pdata)
让PG跟Pdata之间越接近越好换句话说就是找到一组generator的参数,让产生出来的让PG跟Pdata之间的Divergence越小越好。
但是在实作上,我们根本无法知道这个Divergence如何去计算。因为我们不知道PG跟Pdata的分布distribution。
不过好在,其实啊,从distribution中抽样(simple)的效果已经够好了。

也就是说,我们不需要知道PG跟Pdata实际长什么样子,只要从PG跟Pdata中抽样去算或者说估测Divergence就可以了。
下面说如何去算这个Divergence。
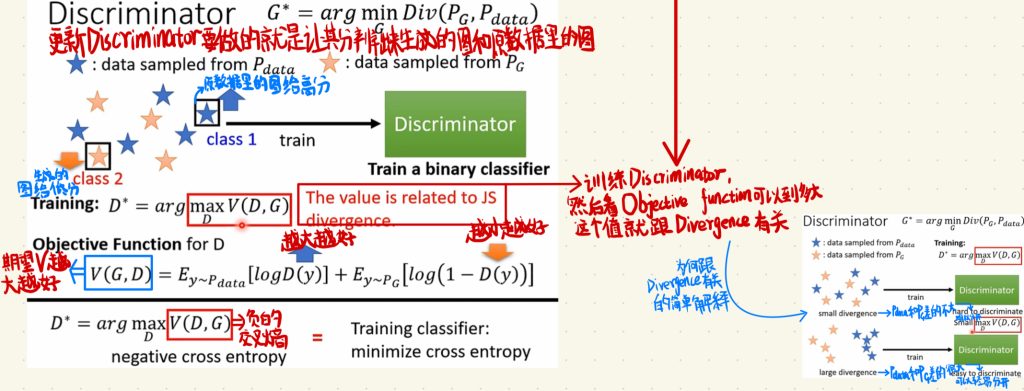
我们更新Discriminator要做的就是让其能分辨出来生成的图和原来数据里的图,让它生成的Scalar给原数据里的图高分,给生成出来的图低分。
上面说的这个操作对应的就是上图右边下面的式子,我们期望的是让Objective Function for D里算出来的V(G, D)的值越大越好。也就是让Objective Function for D式子里面的logD(y)越大越好,然后让log(1 – D(y))越小越好。
Discriminator就是一个分类的Network,之前的课程里面说评价一个分类的Network效果好坏的指标是交叉熵(cross entropy),我们得到的这个V(G, D)就是一个负的交叉熵,所以这个值就可以去评判分类器的好坏。
然后这个Training里面的D*值,其实是和JS divergence有关的。
所以回到我们刚才的如何计算divergence值的问题,我们要做的就是训练一个Discriminator,然后看Objective function可以到多大,然后这个最大的值就是和divergence有关,也就是大致可以看作divergence。
至于为什么这个值和divergence有关,这里只做一个简单的解释。
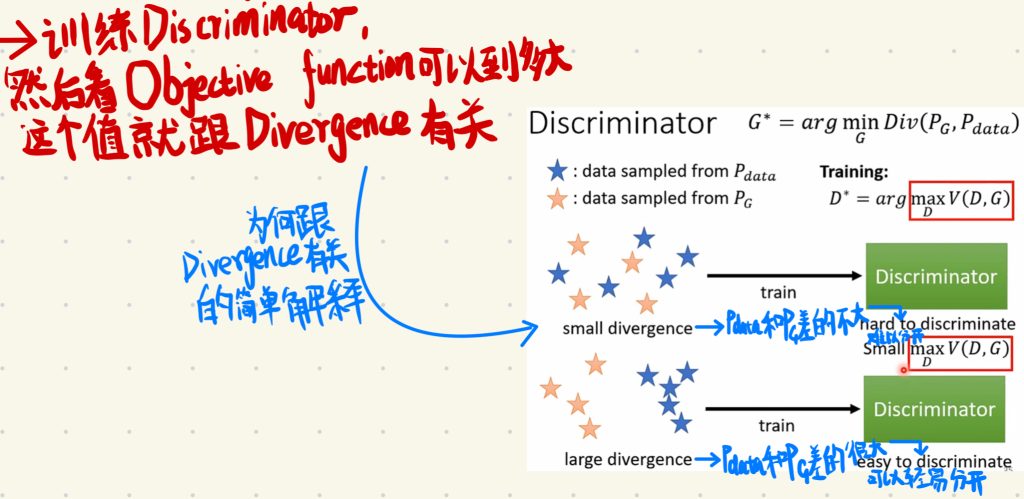
就是小的divergence,它的意思就是PG跟Pdata之间差的不是很大,就是说它们难以分开,这个就对应了V(D, G)的值比较小。反过来说,就是大的divergence,它的意思就是PG跟Pdata之间差的很大,就是说它们可以轻易分开,这个就对应了V(D, G)的值比较大。
让然这个只是一个简单的解释,如果不能让你信服,可以去找到课程里面GAN最原始的那篇Paper,里面应该写的会比较详细。
因为divergence不好求,所以我们选择求最小的V(PG, Pdata)用近似值来代替。我们在做这一步的时候就是如下图里面这样期望G这里小,D这里的大。然后用这个D里面最大的V(D, G)联系到JS divergence。

我们刚刚说的这些操作,其实就对应的是上次GAN里面说的训练步骤:先固定住generator然后更新discriminator,再固定住discriminator,然后更新generator。
当然你也可以不是使用JS divergence,还有许多divergence可以去联系,不过需要一些特殊的方法,你可以去看看下面对应的Paper。

这里课程里面老师其实也没有介绍divergence是什么啦,如果你对这个divergence是什么感到疑惑并且像知道这是什么的话可以在网路上面自己去学习。
根据上面的这些讲解,你就可以发现其实训练一个GAN是很困难的。正所谓“NO PAIN NO GAN (GAIN)”嘛,所以我们需要一些训练GAN的小tips。

首先要说明的是,刚才我们去联系的JS divergence其实不是真正的JS divergence,是做了一些修改的JS divergence,因为真正的JS divergence其实是不适合用在GAN上面的。
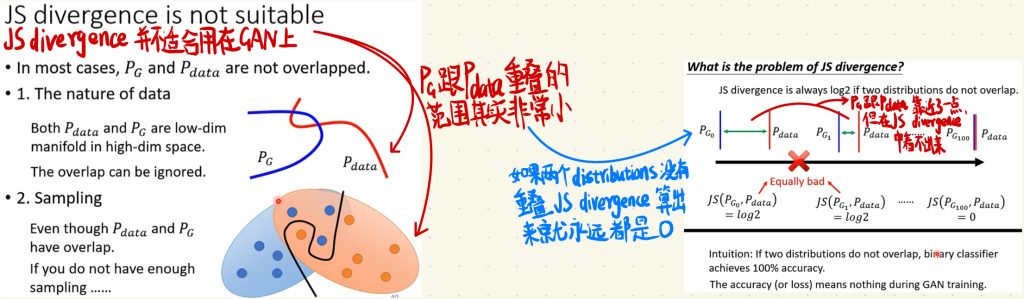
因为如果两个Distribution如果没有重叠的部分的话,JS divergence算出来的结果就永远是0。
但又恰恰其实在GAN中,PG跟Pdata重叠的范围其实是非常小的。
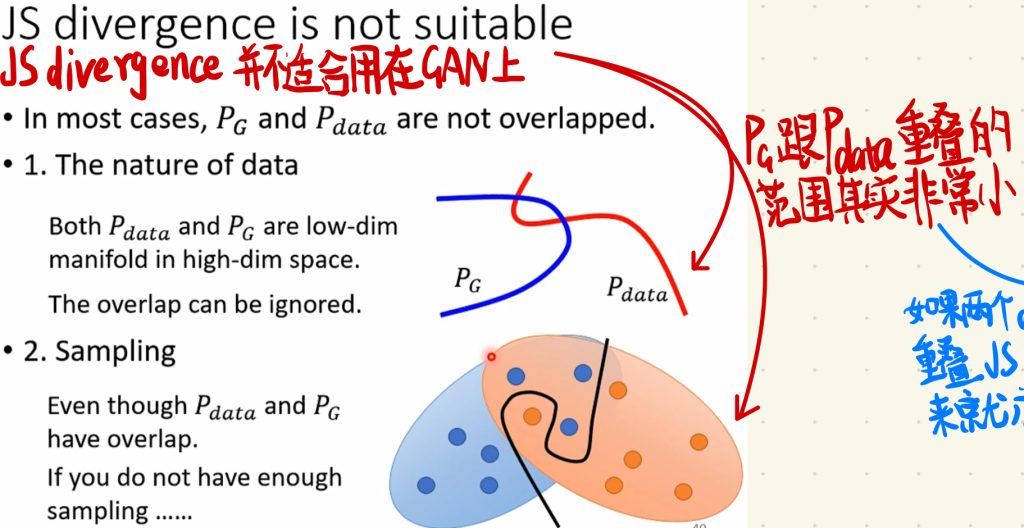
这也就导致了,我们在一步步训练generator的时候,让PG跟Pdata慢慢靠近,直至近乎重叠,但是在还没有开始重叠,PG跟Pdata只是慢慢靠近的时候,JS divergence上面是看不出来的,我们并不知道一开始generator是不是有在真正变好。
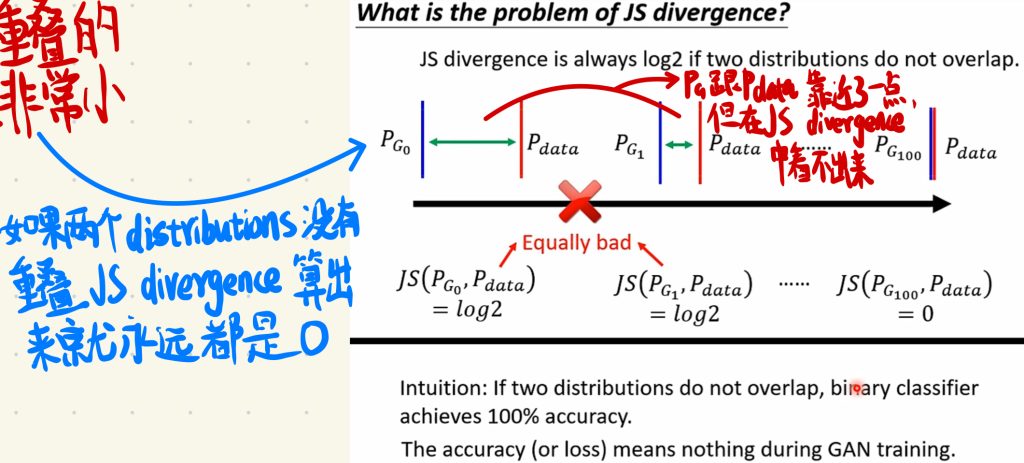
所以我们也在考虑是不是可以换一个指标去衡量PG跟Pdata是否在接近。我们将PG跟Pdata直接的距离写成d,让这个d作为PG跟Pdata是否接近的指标。
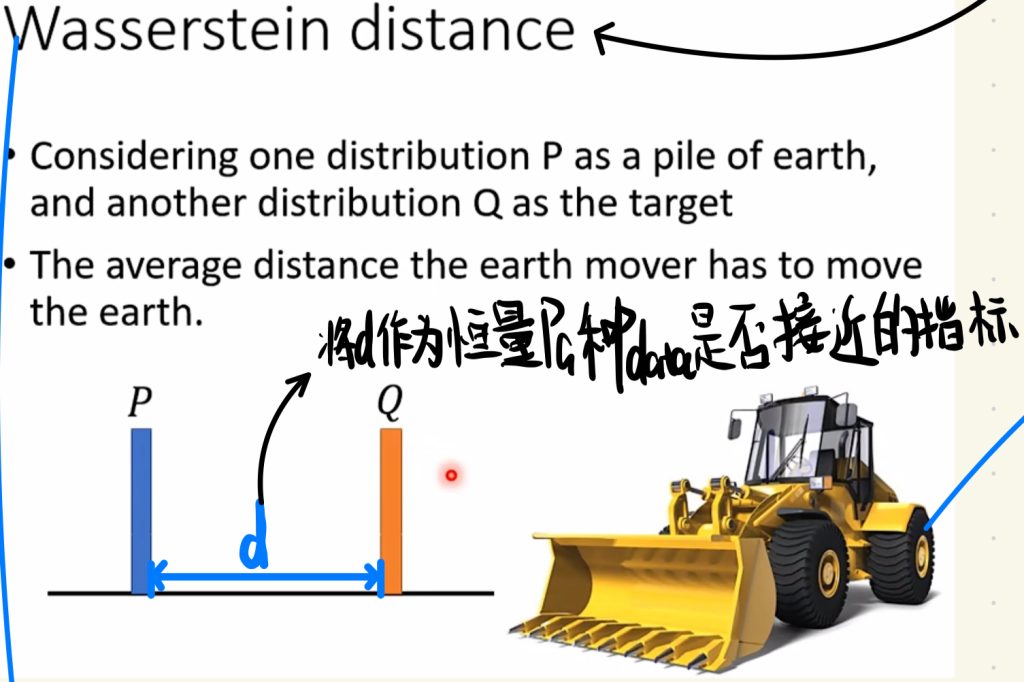
那这个操作其实很想推土机啦,就是把一开始不像Pdata的PG做一些变化,把它“推”成Pdata的样子,然后我们枚举PG平均推土最短的距离当作Wassertein distance,这个Wassertein distance作为新的衡量PG跟Pdata是否接近的指标d。
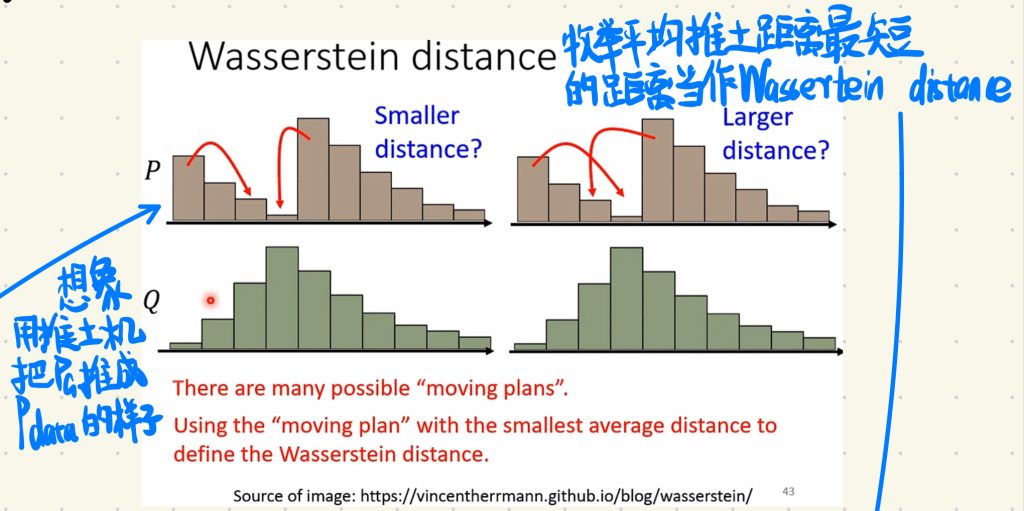
但枚举每一个“推土”的情况其实又是一个Optimization的问题,就会很难去算。但是这里我们先不去管这个Wassertein distance怎么计算,我们先看看用了Wassertein distance后可以达到什么样子的效果。
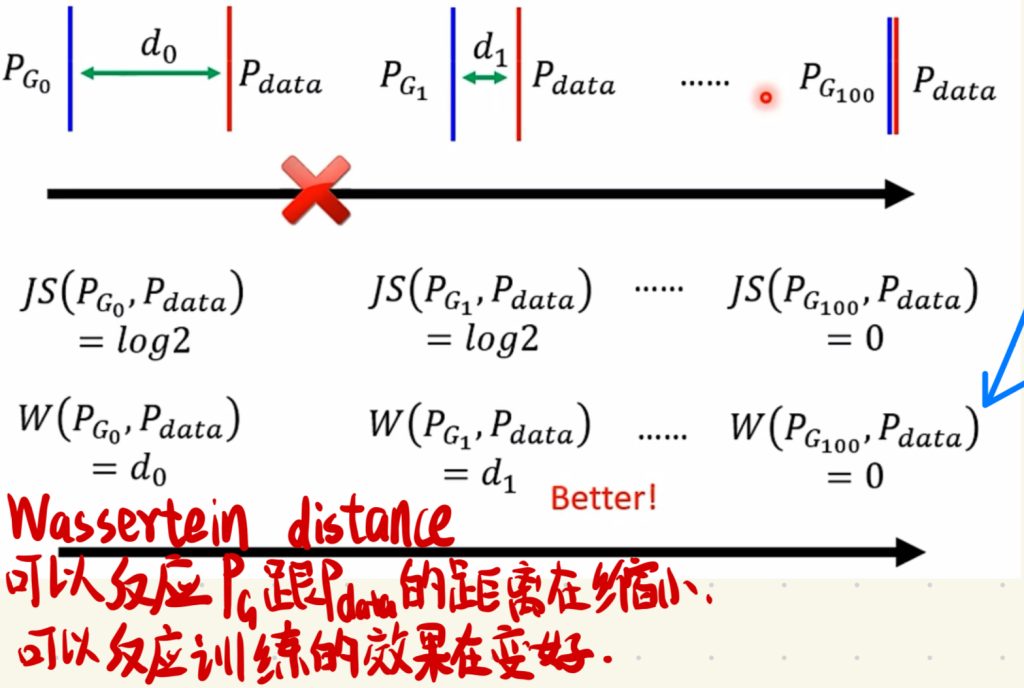
我们使用Wassertein distance当作PG跟Pdata是否接近的指标以后,我们可以看到随着generator生成出来的图片效果的变好,会产生不一样的Wassertein distance值,然后这样就可以反映出PG跟Pdata之间的距离在缩小,就可以反映出来训练的效果会变好。
(这里上图做笔记的时候错别字有点多QQ)
于是乎,我们用Wassertein distance改进了原来的GAN,这个用了Wassertein distance的GAN就叫做WGAN。
刚刚我们说就算Wasserstein distance的问题就相当于Optimization的问题,但是Optimization的问题是比较棘手的,这里我们直接说结论,我们只要解下面这个式子就可以得到Wassertein distance。
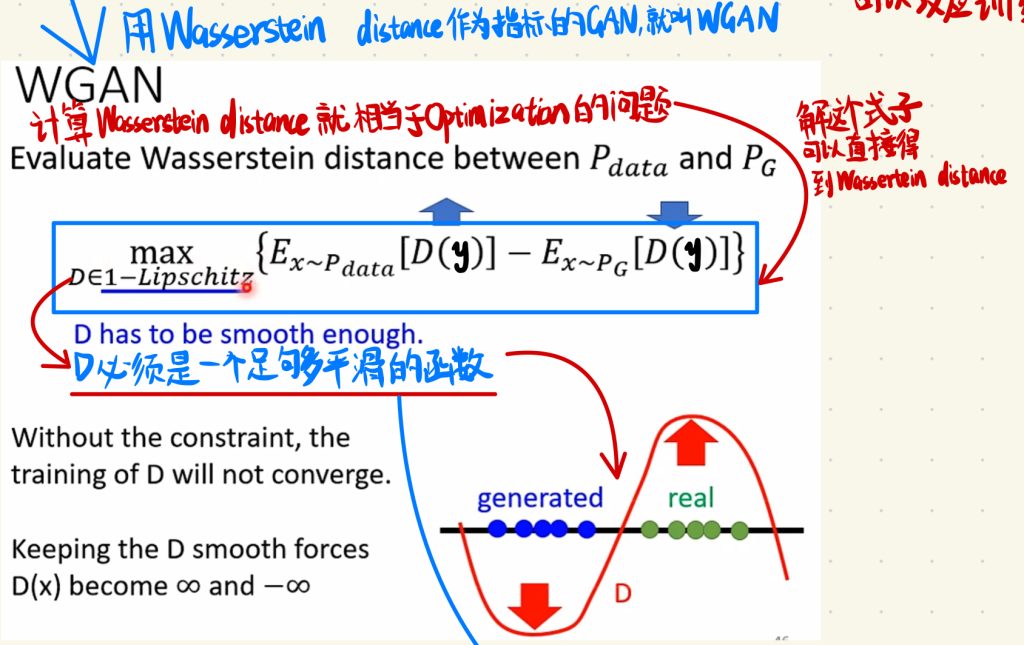
这里需要保证的是,这个式子里面的D必须要是足够平滑的函数。
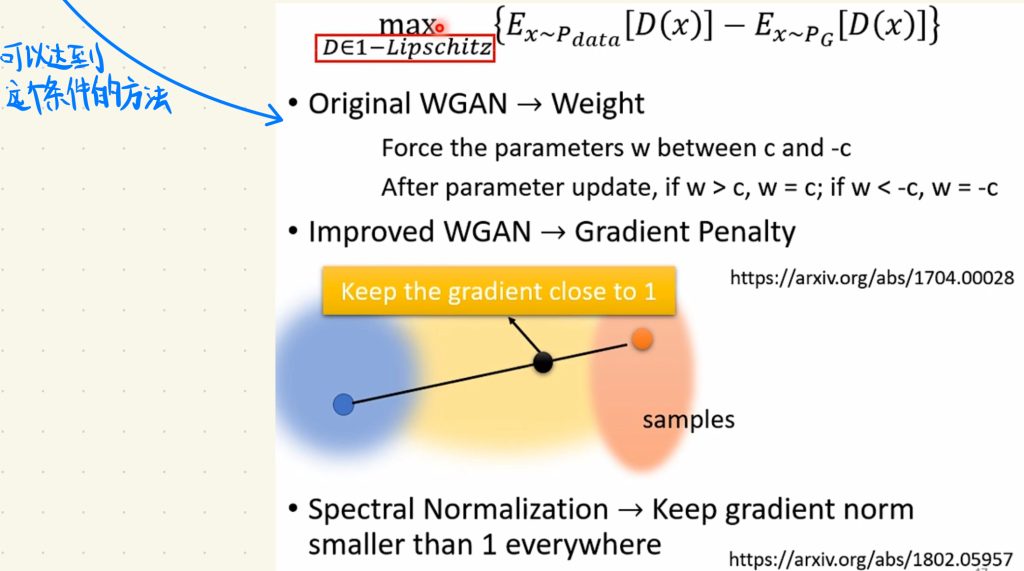
要达到D必须要是足够平滑的函数的这个要求,我们需要用下图的这个方法,这里就不做讲解,如果感兴趣可以去看看图片里面理解里的arxiv的Paper。
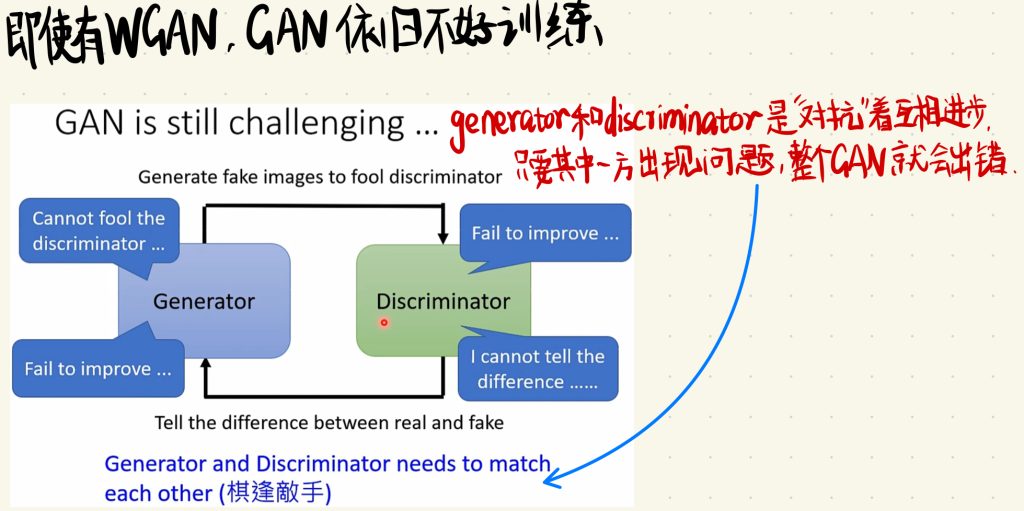
不过即使是有的WGAN,训练GAN依旧不是一个很容易的问题。GAN一直是以难train出名的。
因为GAN的核心就是让generator和discriminator两个神经网络互相“对抗”,互相“成长”的,这也就意味着只要两个神经网络中的任何一个出了问题,整个GAN就会出现问题。
也就是说我们的generator和discriminator是要“棋逢对手”的。
然后GAN不仅是可以用在图像的生成上面,同样也可以用在文字生成上面。但是用GAN去生成文字是一个爆炸难的事情。
那生成的方法其实和图像生成没有什么不同,也是让discriminator去监督,decoder去生成。但是在文字生成的时候有一个问题,就是在generator里面我们取生成的字的时候是那decoder输出的最大值的分数去取值的,因为是取最值的关系,decoder有小小的变化是影响不到discriminator输出的分数的,也就是discriminator是感受不到generator做出的小小的变好的,这样也不能给到generator反馈,generator就不知道自己刚刚生成出来的字是不是正确的,它就直接迷惑了。
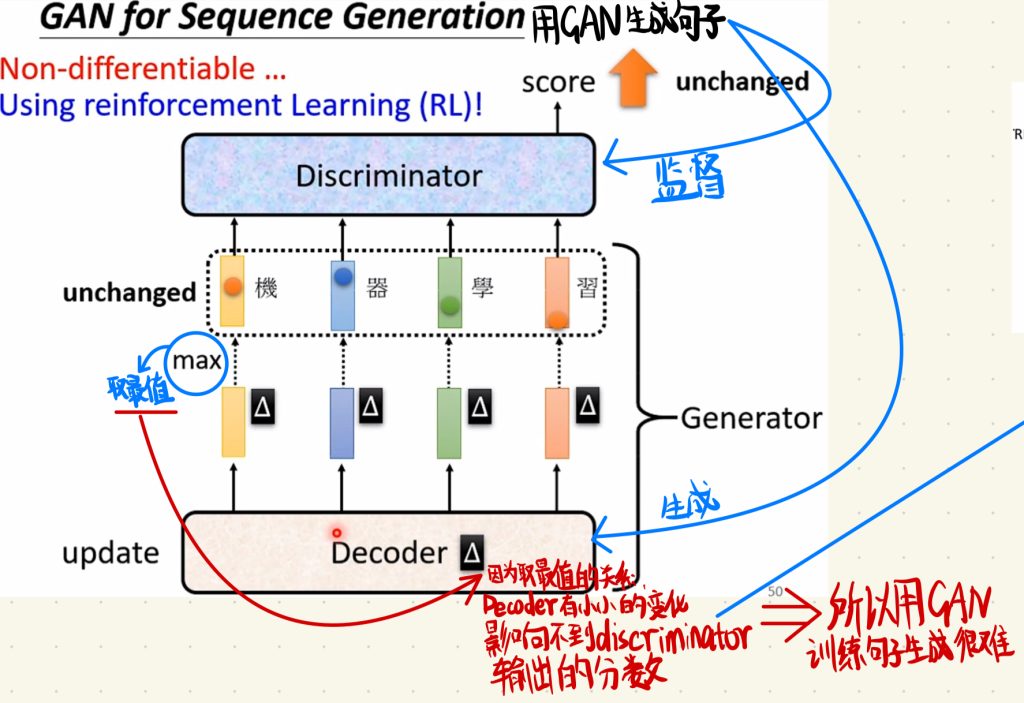
所以说用GAN去生成文字是很困难的。
但是你也可以用强化学习(Reinforcement learning)强行硬train一发。
不过RL同时也是以难train闻名。
两个难train的问题加起来,难度直接就爆炸了!

当然也是有人做出来用GAN生成文字的,你感兴趣的话可以自己去看看Paper。
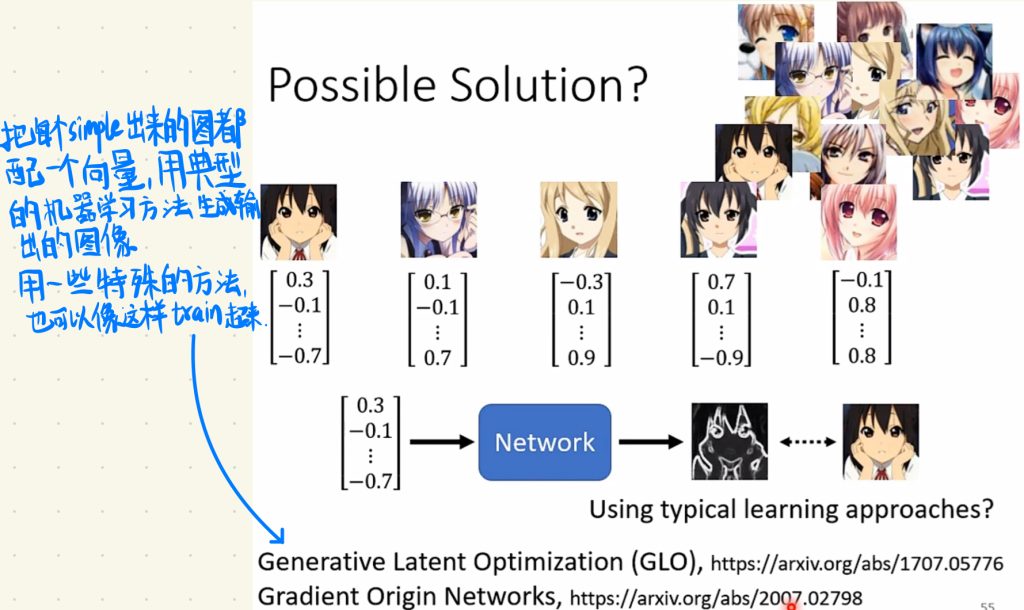
最后,我们生成图像其实也不一定要用到GAN,也可以把每一个simple出来的图都配一个向量,用典型的机器学习方法去生成一个输出的图像,然后用一些特殊的方法也可以train起来。不过这样可能啊,我是说可能会有一些问题在一些特殊的问题上,谁知道呢。这里也只是提供一个思路。
评估一个生成器的方法
下面我们来说评估一个生成器的方法。
在一开始用机器学习的方法去生成一个图像的时候,Paper里面直接就用人眼看生成的图像,说它生成的好坏这样子就结束了。
但是其实你知道说用人眼看其实是不准确和客观的。

所以我们想有一个评价generator生成出来的图像好坏的指标。
我们的做法其实就是把generator生成出来的图像放到一个影像分类系统当中,输入的分布结果越集中,就说明generator产生出来的图片效果越好。
但是这里有一个Mode Collapse的问题。
就是说discriminator可能会遇到一个盲点,就是只有一种simple出来的图分辨不出来,但是generator就相当于就是发现了“bug”知道吗,然后generator就会和我们找到bug一样,不停地对着一个bug薅下去。generator说既然我生成出来这种类型的图片discriminator分辨不出来,那我就一直照着这个图片的样子生成一堆差不多的图片下去,然后这些图片其实都是差不多的,最后生成出来的照片同质化很严重。
比如下图这里蓝色框框出来的图片,generator它生成出来了差不多的一大堆。

那目前还没有解决这个Mode Collapse问题很好的方法。一般在训练的时候,我们就每隔一段时间输出一次图像,然后遇到Mode Collapse问题的时候就停下来这个样子。
然后我们来说说多样性评价的方法。
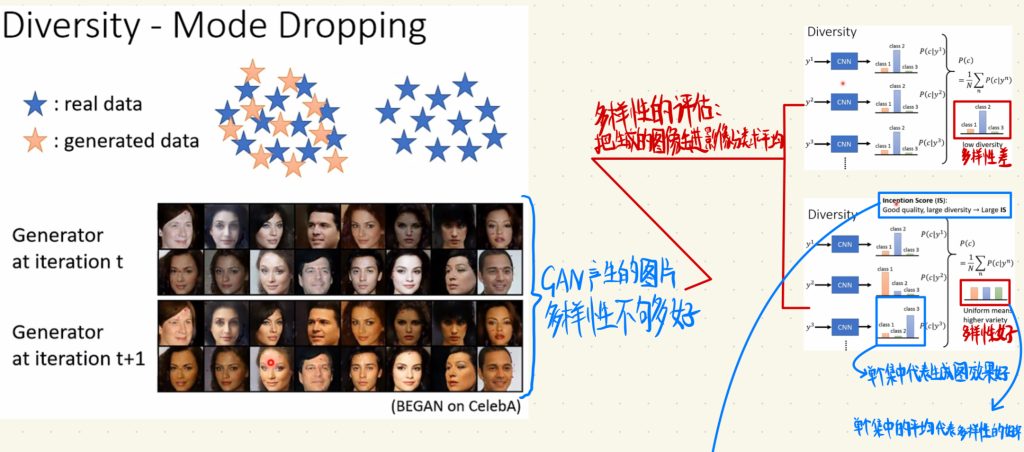
上图中左边那些生成出来的人脸就是多样性不够好的例子。(人家不知道的人可能还以为是什么种族歧视[doge])
我们去评价生成出来图像好坏的方法就是把生成的图像丢进影像分类系统里面求平均。
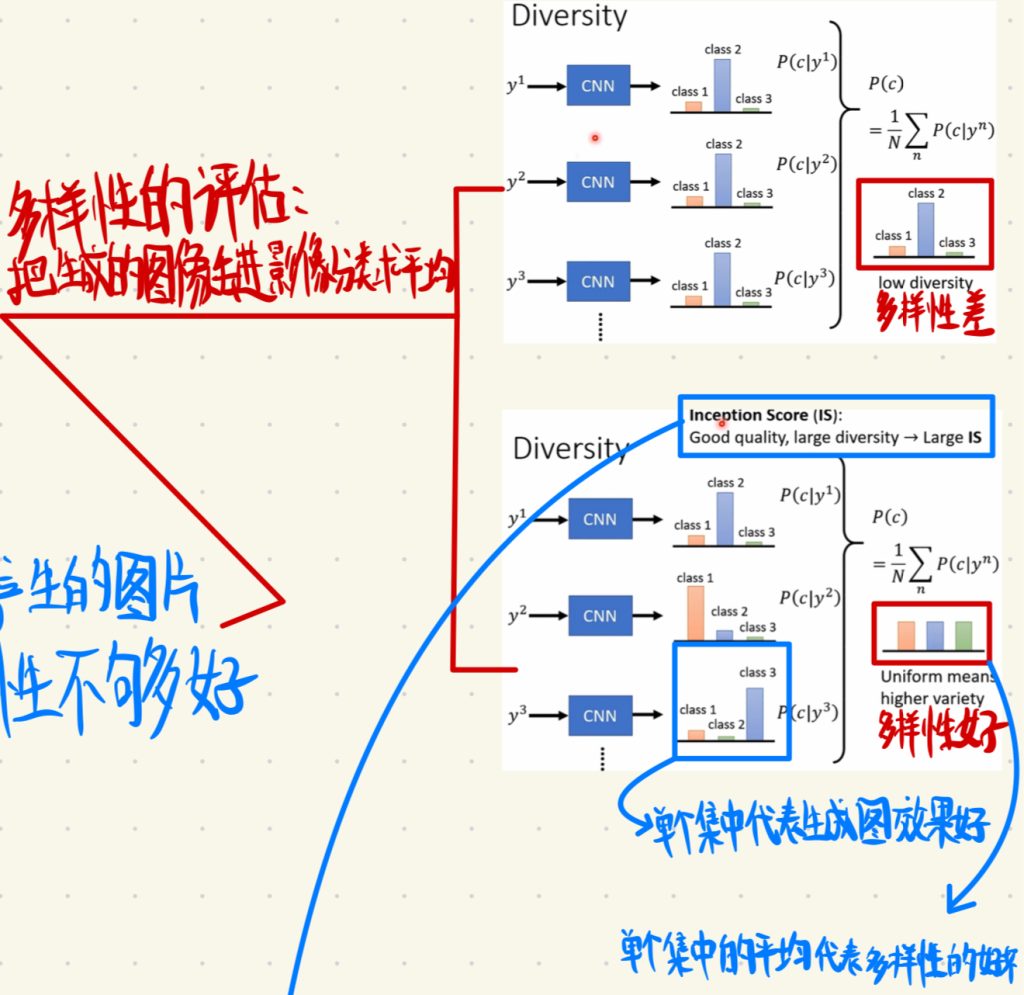
这里注意不要和前面搞混了,我们把生成出来的图像单个丢进影像分类系统(这里举例用的是CNN)里面,然后出来单个结果集中代表的是生成图的生成效果好。然后我们把这些单个集中的结果做一个平均得到的另外一个平均的结果表示的就是生成出来图形的多样性,如果平均出来的结果集中就说明多样性差,反过来说如果平均出来的结果分散就代表多样性好。
然后上面这个IS就可以作为评估生成器生成的图片质量和多样性好坏的指标。

不过平均生成图好坏的指标不止有IS啦,还有很多其它的,这里再贴一个FID指标,这里就不对FID再做讲解了。
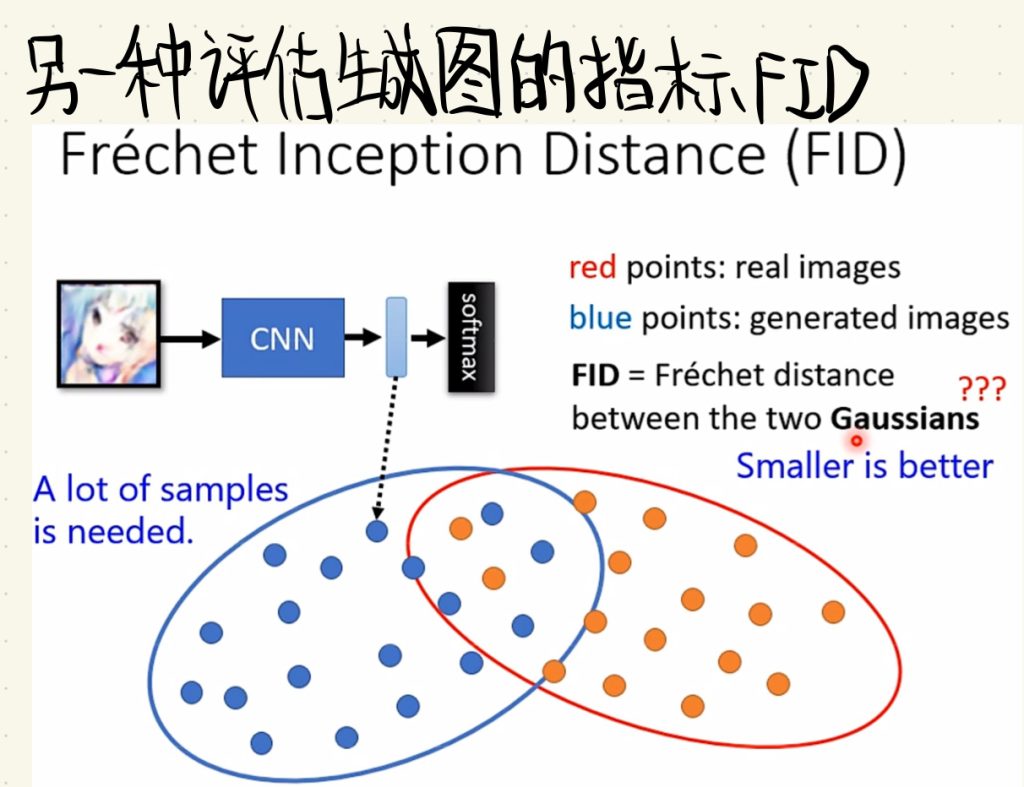
但是啊,但是,对于GAN的评估依旧很难,就比如假设generator现在不知道为什么,它就是没有生成新的图片,它就把原来的资料集复制一遍,或者做一个方向转变就输出了,这样子以上说的所有指标就都无效了,因为即使generator什么都没有学到,但是最后得到的分数还是会很好。

所以,即使是GAN的评估也会是一个值得研究的问题,这个评估的指标也可以发Paper。
然后要说的是条件限制的GAN生成。
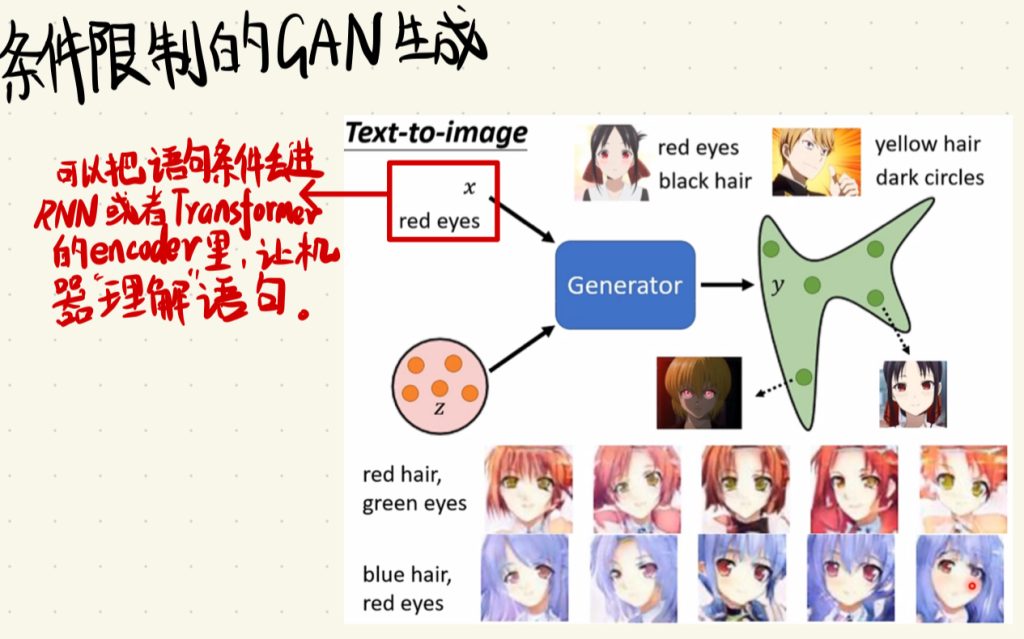
最早前面那篇关于GAN的笔记里面我们讲到说,丢进generator里面的是一个输入x和一个distribution,现在我们就把这个x给加回来,这个x就是我们想让generator生成图片的条件。
比如你可以把限制条件的语句丢进RNN或者Transformer的encoder里,让机器“理解”语句。
没错这样子就结束了。
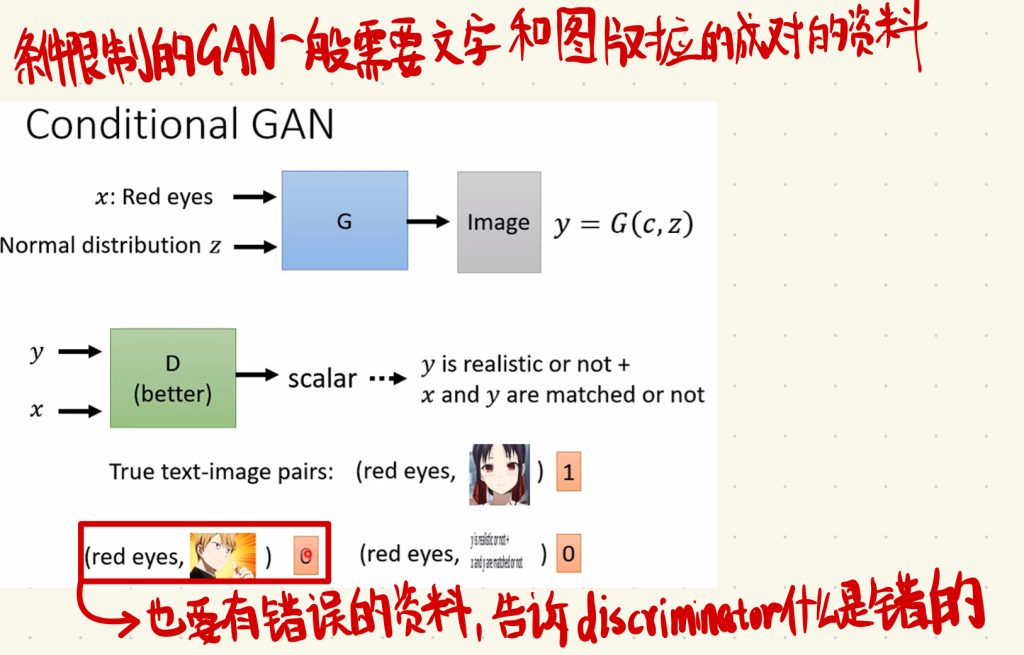
这样子你就需要文字和图片对应的成对的一个pair的资料。然后这个资料里面最好也要有错误对应的资料,告诉discriminator说什么样子的图片和条件对应是错误的,以不至于让discriminator遇到错误生成的时候不知道怎么处理。
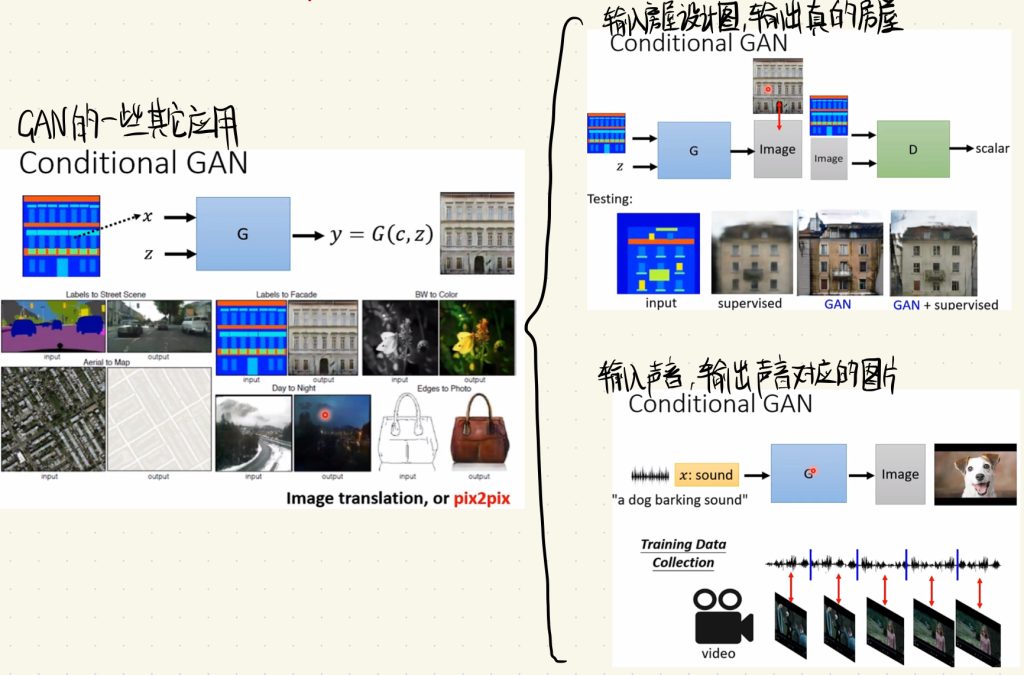
下面是一些GAN其它方面比较有意思的应用。
比如输入房屋的设计图,输出真的房屋。
再比如输入声音,输出声音对应的图片。
无监督式学习的GAN
最后我们来讲一个比较神奇的,就是无监督式学习的GAN。
在一些情况下面我们可能没有办法拿到成对能对应起来的资料集。就比如影像风格转换的问题上面,我们希望输入的是三次元人物的图片,然后输出的是二次元人物风格对应的样子,这样的资料集对应我们是一对都找不到的,因为如果你把一堆三次元人物的图片叫人画成对应的二次元样子,那成本就太大了,很明显不现实。
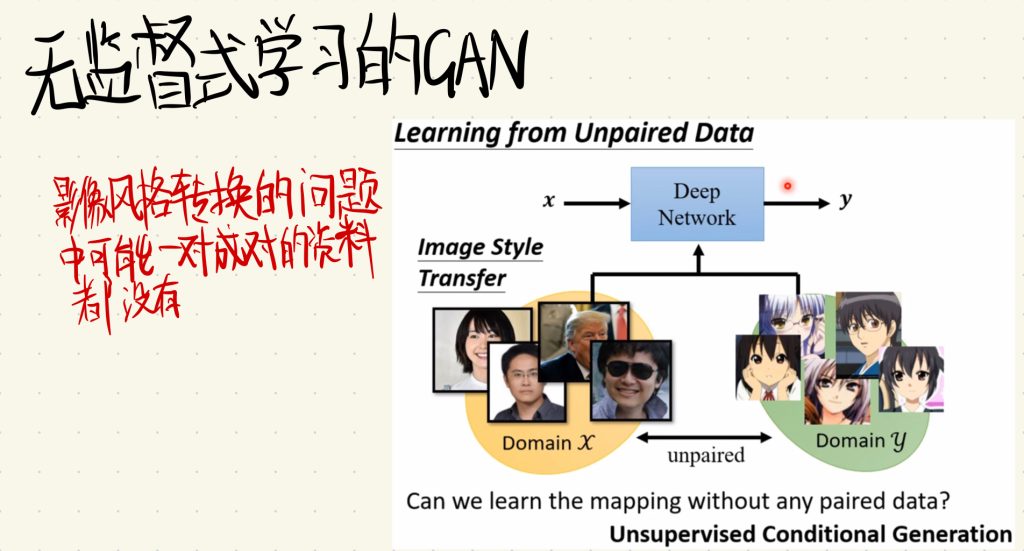
这里我们输入的资料集就是不匹配对应的资料,一堆是三次元人物的图片,然后一堆是二次元人物风格的图片。
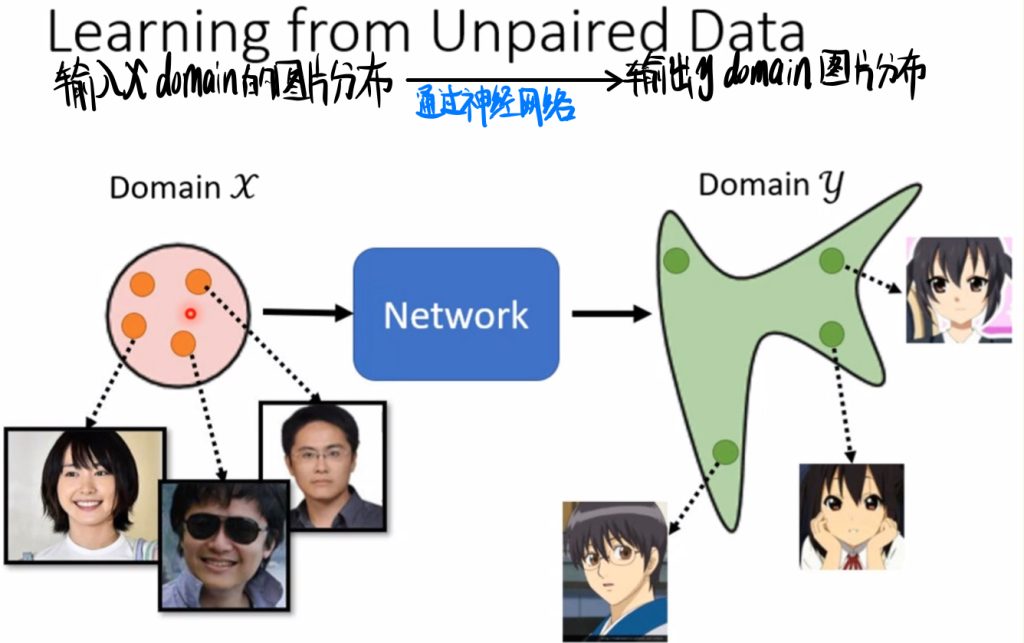
这里把三次元人物图片作为domain x,把二次元风格的人物图片作为domain y。
我们要做的就是输入x domain的图片分布,然后通过神经网络输出y domain图片的分布。
因为没有成对的资料,最大的问题就是discriminator就没有办法判断生成的图片到底对不对。
这里我们的解决方法就是先用一个generator,把x domain的图片转换成我们要的二次元的y domain的图片。然后再用一个generator,把y domain的图片还原成三次元x domain的样子。最后我们比较这两边图片向量,因为图片可以看作是向量嘛,所以我们只要比较两个图片向量之间的距离就可以知道generator生成的图片对不对了。
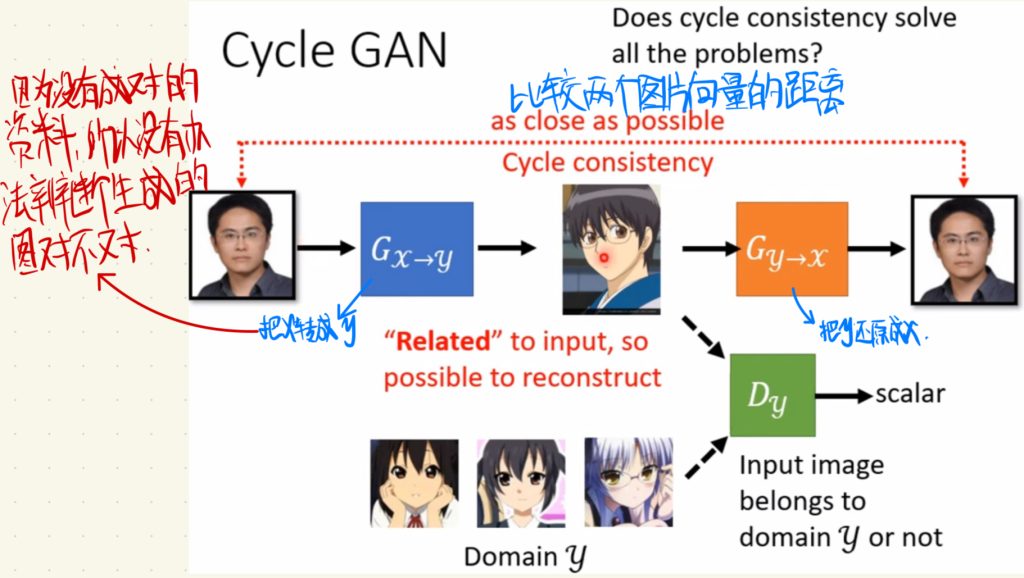
这个思想就是Cycle GAN。
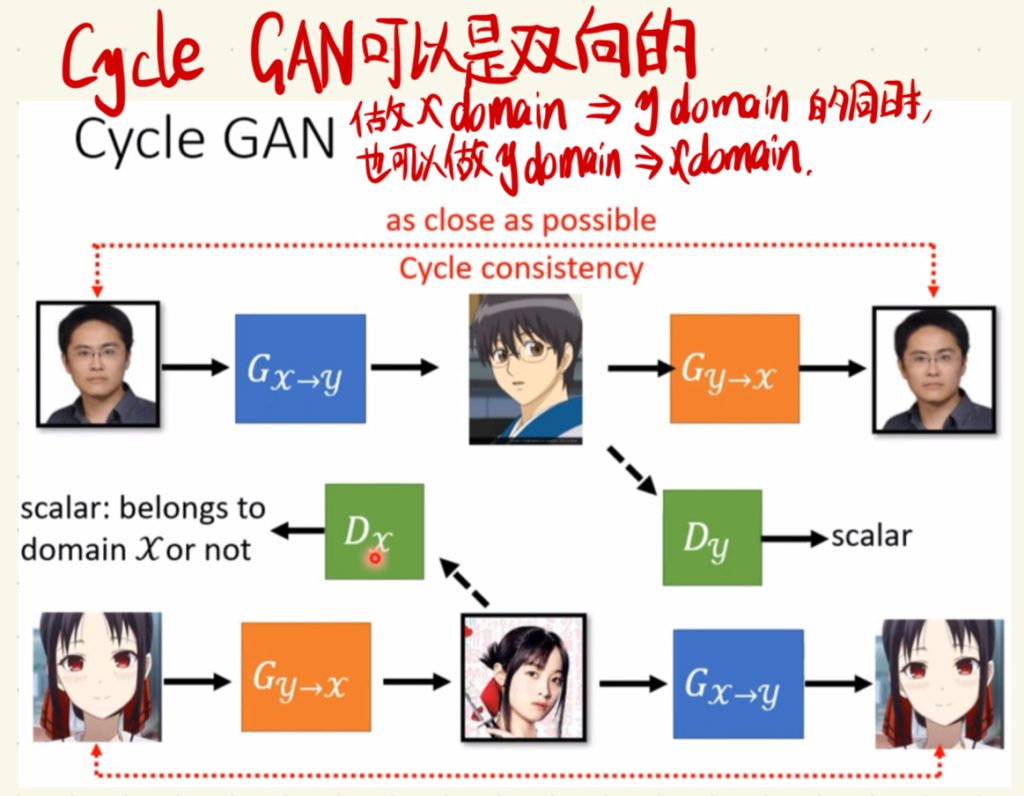
Cycle GAN可以是双向的,就是做x domain到y domain的同时,也可以做y domain到x domain。这样子就构成了一个圈或者说循环了。所以这样子的GAN就叫做Cycle GAN。
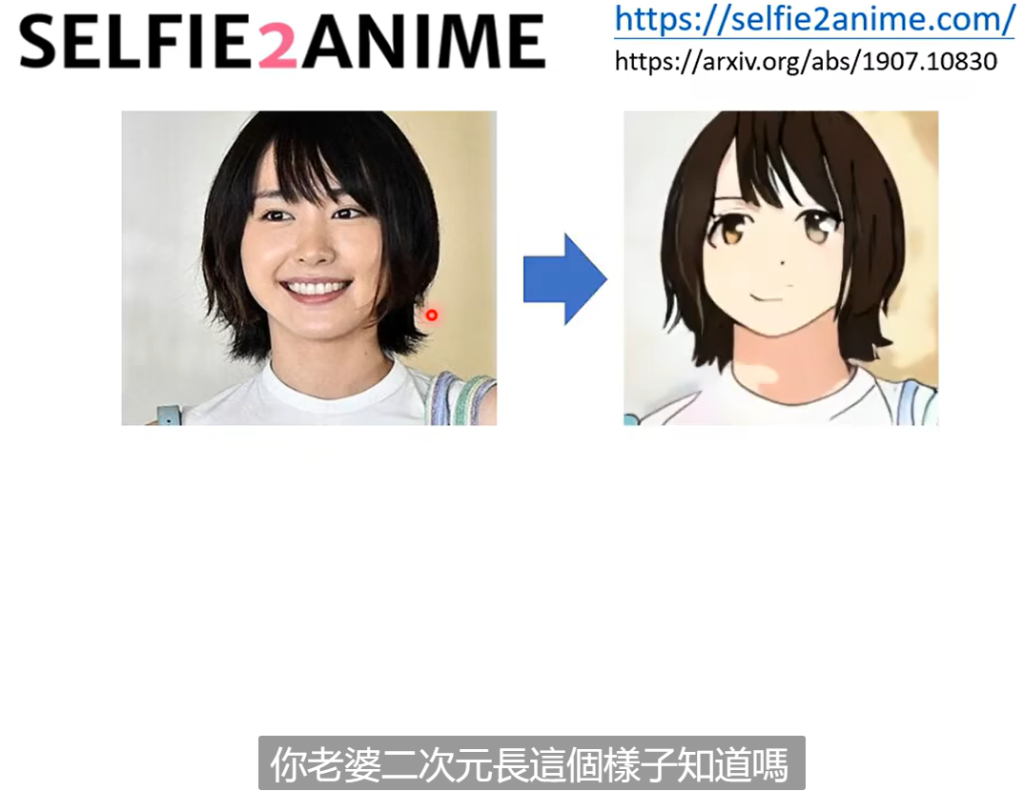
这个三次元转二次元的模型其实已经有团队做出来了,还是挺好玩的,下图里面有这个风格转换的web,如果感兴趣你也可以去玩玩。
这里放一个转换之后的效果,引用一件李老师课上的原话,“你老婆二次元张这个样子知道吗”(xswl)。
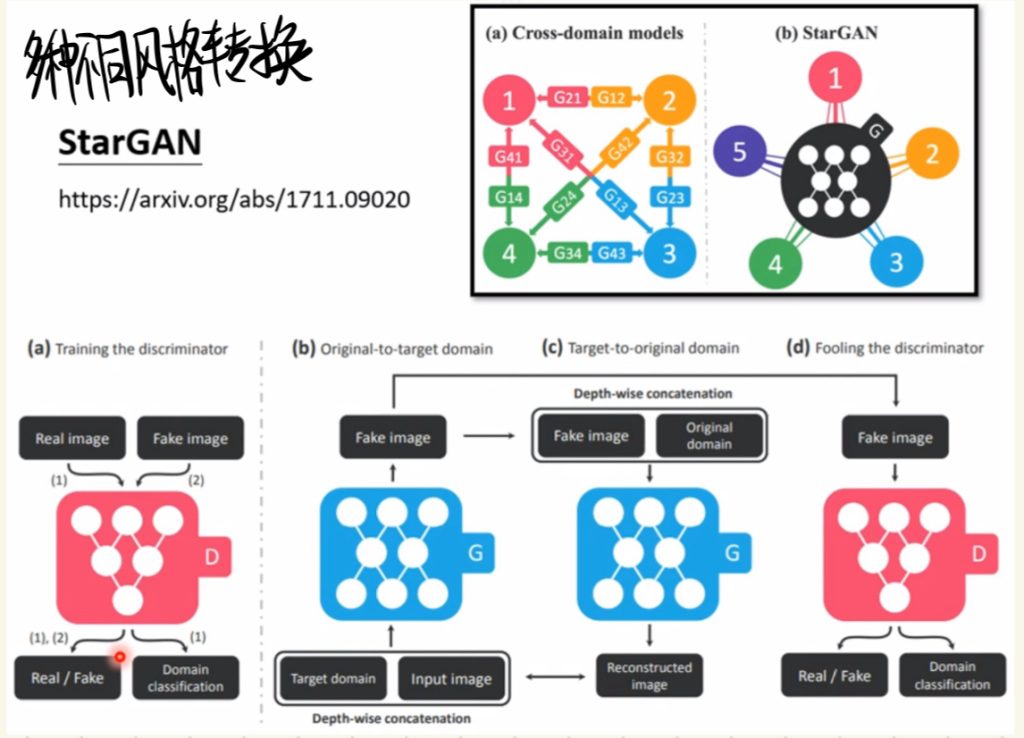
当然还有多种不同风格转换的Star GAN。
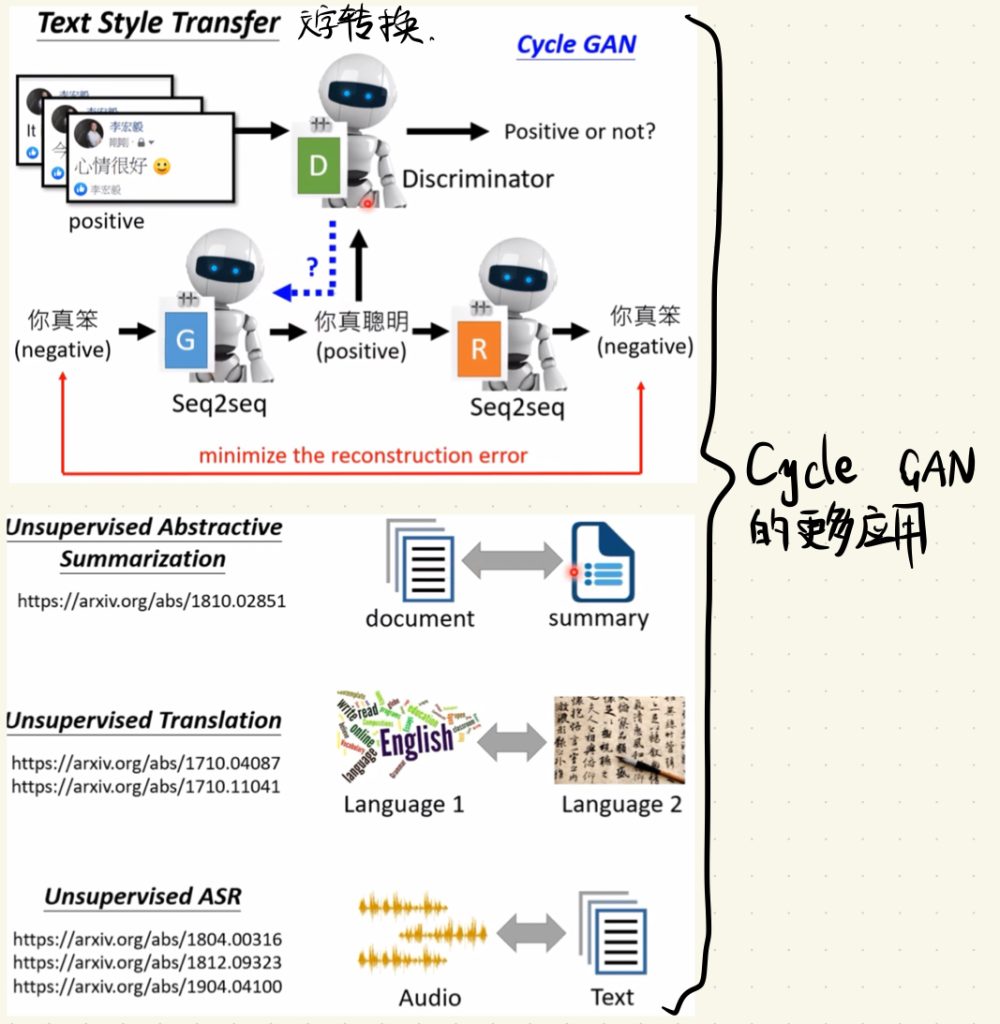
然后Cycle GAN还有更多不同的应用场景。
比如文字语义褒贬转换(我也不知道有什么用就是了)、把完全没有关系的文章和其它文章的摘要作为输入让机器学会做摘要的能力、把完全没有语义对应的语言文本作为资料去训练模型让机器学会翻译和把完全没有对应关系的语音和文本拿去训练让机器学会语音转文本(最后两个加起来岂不是跨物种交流指日可待了?!!![doge])。
以上就是关于GAN剩下内容比较杂的笔记内容。



评论