
本篇文章主要是我用来应付期中考试的复习资料汇总,有些地方可能不是非常详细,不过应该还是挺适合复习和查询一些容易遗忘的知识的。
概念部分(八股文)
数据库系统概述
数据库的4个基本概念
数据库的四个基本概念数据、数据库、数据库管理系统和数据库系统:
- 数据:描述事物的符号记录。
- 数据的含义称为数据的语义,数据与其语义是不可分的。
- 数据库:是长期存储在计算机内有组织、可共享的大量数据的集合。
- 数据库中的数据按一定的数据模型组织、描述和存储,具有较小的数据冗余(data redundancy)、较高的数据独立性(data independency)和可扩展性(scalability)。
- 数据库管理系统:位于用户与操作系统之间的数据管理软件,是计算机的基础软件。
- 数据库管理系统的主要功能包括:数据定义功能(数据定义语言(data definition language, DDL));数据组织、存储和管理功能;数据操纵功能;数据库的事务管理和运行管理功能;数据库的建立和维护功能;其它功能;
- 数据库系统:是指由数据库、数据库管理系统(及其应用开发工具)、应用系统和数据库管理员(data administrator, DBA)组成的存储、管理、处理和维护数据的系统。
数据管理技术的产生和发展
数据管理技术经历了人工管理、文件系统、数据库系统三个阶段。
- 人工管理阶段:20世纪50年代中期以前。
- 文件系统阶段:20世纪50年代后期~20世纪60年代中期。
- 数据库系统阶段:20世纪60年代后期以来。
数据库系统阶段的数据具有如下特点:
- 整体数据的结构化
- 数据的共享性强、冗余度低且易于扩充
- 数据的独立性强:数据的物理独立性和数据的逻辑独立性
- 数据由数据库管理系统统一管理和控制:数据的安全性保护、数据的完整性检查、数据的并发性控制、数据库的恢复
数据模型
数据模型也是一种模型,它是对现实世界数据特征的抽象。数据模型是数据库系统的核心和基础。
数据模型可以分为:
- 概念模型
- 逻辑模型&物理模型
概念模型
概念模型用于信息世界的建模。信息世界中的基本概念:
- 实体:客观存在并可相互区别的事物
- 属性:实体所具有的某一特性
- 码:唯一标识实体的属性集
- 实体类型:具有相同属性的实体必然具有共同的特征和性质
- 实体集:同一类型实体的集合称为实体集
- 联系:实体(型)内部的联系和实体(型)之间的联系(实体内部的联系通常是指组成实体的各属性之间的联系,实体之间的联系通常是指不同实体集之间的联系)
实体之间的联系有一对一、一对多、多对多等多种类型。
数据模型的三要素
数据模型通常由数据结构、数据操纵和完整性约束三要素组成:
- 数据结构:描述数据库的组成对象以及对象之间的联系。
- 数据操纵:对数据库中各种对象(型)的实例(值)允许执行的操作的集合,包括操作及有关的操作规则。
- 完整约束性:一组完整性规则。
数据模型可以分为:层次模型(树状结构)、网状模型、关系模型。
层次模型简单但不能解决多对多的关系。
层次模型的数据操纵主要有查询、插入、删除和更新操作。
层次模型的优缺点:
- (优点)层次模型的数据结构比较简单清晰
- (优点)层次数据库的查询效率高
- (优点)层次数据模型提供了良好的完整性约束支持
- (缺点)现实世界中很多联系是非层次性的
- (缺点)如果一个结点具有多个双亲结点,用层次模型表示这类联系就很笨拙
- (缺点)查询子女结点必须通过双亲结点
- (缺点)由于结构严密,层次命令趋于程序化
总之,用层次模型对具有一对多层次联系的部门描述非常自然、直观,容易理解。
网状模型
网状数据库系统采用网状模型作为数据的组织方式,其典型代表是DBTG系统,亦称CODASYL系统。
把满足一下两个条件的基本层次联系集合称为网状模型:
- 允许一个以上的结点无双亲结点
- 一个结点可以有多于一个的双亲结点
网状模型比层次模型更具有普遍性,它去掉了层次模型的两个限制,允许多个结点没有双亲结点,且允许结点有多个双亲结点。
网状模型的优缺点:
- (优点)能够更为直接地描述现实世界
- (优点)具有良好的性能,存取效率较高
- (缺点)结构比较复杂
- (缺点)数据定义语言和数据操场语言比较复杂
- (缺点)用户必须了解系统结构的细节,加重了编写应用程序的负担
关系模型
关系模型是最重要的一种数据模型。
关系模型中的一些术语:
- 关系:对应通常说的一张二维表
- 元祖:表中的一行
- 属性:表中的一列
- 码:又称码键或键,是表中某一个属性或一组属性
- 域:表示某一属性的取值范围
- 分量:元祖中的一个属性值
- 关系模式:对关系的描述
关系模型要求关系必须是规范化的。关系的每一个分量必须是一个不可分的数据项。
不允许表中还有表。
关系模型的数据操纵主要包括查询、插入、删除和更新数据。
关系的完整性约束包括实体完整性、参照完整性和用户定义的完整性三大类。
关系模型的优点:
- 关系模型建立在严格的数学概念基础上。
- 关系模型的概念单一。
- 关系模型的存取路径对用户隐蔽。
数据库的三级模式结构
- 模式(逻辑模式):是数据库中全体数据的逻辑结构和特征的描述,是所有用户的公共数据视图。
- 外模式(子模式或用户模式):是数据库用户能够看见和使用的局部数据的逻辑结构和特征的描述,是数据库,是数据库用户的数据视图,是与某一应用有关的数据的逻辑表示。
- 内模式(物理模式或存储模式):是数据物理结构的存储方式的描述,是数据在数据库内部的组织方式。
关系操作
关系模型中常用的关系操作包括查询操作和更新操作两大部分。而更新操作又可分为插入、删除、修改等。
关系的完整性
关系模型中有三类完整性约束:实体完整性、参照完整性和用户定义的完整性。
实体完整性约束:若属性A是基本关系R的主属性,则不能取空值。
专门的关系运算包括选择、投影、连接、除等运算。
各种运算可以记为:
- 并:R ∪ S
- 差:R – S
- 交:R ∩ S
- 笛卡尔积:R x S
- 选择:σF(R)
- 投影:ΠA(R)
- 连接:R ⋈ S
- 除:R ÷ S
约束项
能够通过某个字段唯一区分出不同的记录,这个字段被称为主键。
外键用于建立表与表之间的关联性。它引用另一张表的主键,确保外键字段的值必须在被引用表的主键中存在,以保持数据的完整性。
数据加密
数据加密主要包括存储加密和传输加密。
代码部分
主要记录一些基本并且常用的SQL代码,以下代码公式中<>中的内容是可以根据实际情况进行修改的。
如果只是不太记得下列公式的一些细节,这里先放一个常用公式的大全,想看每个公式详细的说明可以继续往下面看:
-- 创建表
CREATE TABLE <表名> (<字段1> <数据类型> <是否为主键> <是否为NULL>, ...);
--创建关联表
CREATE TABLE <表名> (<字段1> <数据类型> PRIMARY KEY, FOREIGN KEY (<当前新创建表的主键名>) REFERENCES <关联表名> (<该关联表的主键>),<字段2> <数据类型> <是否为NULL>, ...);
--删除表
DROP TABLE <表名>;
-- 修改表的若干操作:
-- 添加列
ALTER TABLE <表名> ADD <列名> <数据类型> <主外键>;
-- 修改列
ALTER TABLE <表名> MODIFY COLUMN <列名> <新数据类型> <主外键>;
-- 删除列
ALTER TABLE <表名> DROP COLUMN <列名>;
-- 添加外键或其它约束
ALTER TABLE <表1名> ADD CONSTRAINT <外键名> FOREIGN KEY (<列名>) REFERENCES <表2名>(<列名>);
-- 插入数据(增)
INSERT INTO <表名> (<字段1>, <字段2>, ...) VALUES (<值1>, <值2>, ...);
-- 删除数据(删)
DELETE FROM <表名> WHERE ...;
-- 查询数据(查)
-- 基本查询
SELECT * FROM <表名>;
-- 条件查询
SELECT * FROM <表名> WHERE <条件表达式>;
--模糊条件查询
SELECT * FROM <表名> WHERE <字段> LIKE '...%';
--排序查询
SELECT <字段1>, <字段2>, ... FROM <表名> ORDER BY <FROM前面的其中若干个字段> <DESC>;
-- 集合查询
SELECT <列名> FROM <表名> WHERE <列名> IN (<值1>, <值2>, <值3>, …);
-- 多表查询
SELECT <若干字段名> FROM <表名1>, <表名2> WHERE <条件表达式>;
-- 聚合查询
SELECT <聚合函数>(<若干字段>) num FROM <表名>;
-- 嵌套查询
SELECT <列名> FROM <表名> WHERE <列名> <运算符> (<子查询>);
-- 更新数据(改)
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;表格操作
创建表
可以通过SQL代码直接创建表格,做法如下:
CREATE TABLE <表名> (<字段1> <数据类型> <是否为主键> <是否为NULL>, ...);常见的数据类型可以查看本文章末尾的常见数据类型汇总部分。若想将该值设为主键,可以在数据类型后面写上PRIMARY KEY,若不是主键则可以不写。可以使用NOT NULL来声明这个字段下的内容不填写时候的情况,比如说INT类型的数据下面,如过设置不为NULL,则会自动填上0而不是NULL。
举例创建一个student表,表中包含学号,姓名,性别列内容:
CREATE TABLE student (学号 BIGINT NOT NULL PRIMARY KEY, 姓名 CHAR(16) NOT NULL, 性别 CHAR(4) NOT NULL);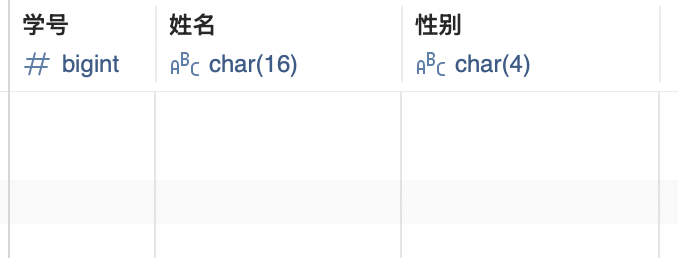
关联表
在了解了主键和外键的定义之后,我们可以再创建一个表,利用REFERENCES将两个表关联起来(FOREIGN KEY (<当前新创建表的主键名>) REFERENCES <关联表名> (<该关联表的主键>)):
CREATE TABLE <表名> (<字段1> <数据类型> PRIMARY KEY, FOREIGN KEY (<当前新创建表的主键名>) REFERENCES <关联表名> (<该关联表的主键>),<字段2> <数据类型> <是否为NULL>, ...);如此我们便可以创建一个新的关联表score,并且两个表中的学号字段是共享的:
CREATE TABLE score (学号 BIGINT PRIMARY KEY, FOREIGN KEY (学号) REFERENCES student (学号), 数据库 INT NOT NULL, 数据结构 INT NOT NULL);
删除表
创建了表之后,我们如果不想要这个表了,便可以使用DROP删除表,其用法非常简单:
DROP TABLE <表名>;需要注意的是,DROP操作会直接删除表,不可复原,所以请谨慎操作!
修改表
一些简单的修改表可以使用ALTER来实现。
-- 添加列
ALTER TABLE <表名> ADD <列名> <数据类型> <主外键>;
-- 修改列
ALTER TABLE <表名> MODIFY COLUMN <列名> <新数据类型> <主外键>;
-- 删除列
ALTER TABLE <表名> DROP COLUMN <列名>;
-- 添加外键或其它约束
ALTER TABLE <表1名> ADD CONSTRAINT <外键名> FOREIGN KEY (<列名>) REFERENCES <表2名>(<列名>);插入数据(增)
使用INSERT在表格中插入数据。INSERT语句的基本语法是:
INSERT INTO <表名> (<字段1>, <字段2>, ...) VALUES (<值1>, <值2>, ...);举例我们在刚刚创建的student表中插入一行数据:
INSERT INTO student (学号, 姓名, 性别) VALUES (2024001, '托比', '男');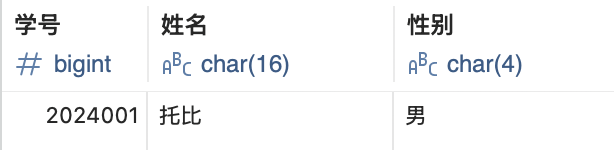
删除数据(删)
可以通过DELETE来删除表格中的某一行数据:
DELETE FROM <表名> WHERE ...;比如我们删除刚刚插入的托比数据,WHERE后面可以写托比这一行的相关条件(学号,姓名,性别任意一项定位即可)即可删除该条数据:
DELETE FROM student WHERE 学号 = 2024001;
DELETE也可以通过条件删除多条数据,首先利用刚才的方法我们先多创建几行数据:
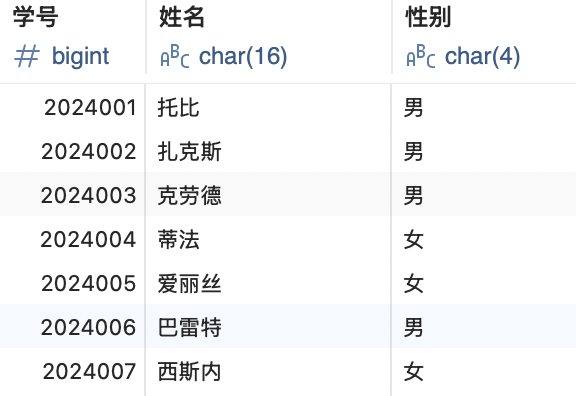
比如我们想要删除所有性别为男的数据,可以这样做:
DELETE FROM student WHERE 性别 = '男';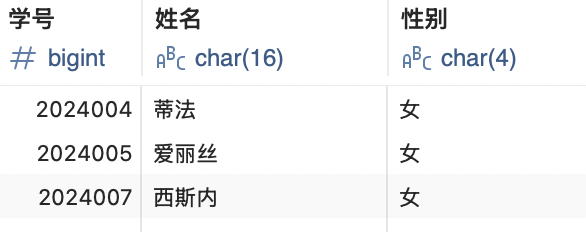
关于DELETE还需要注意的两点是:
- 如果没有查询到
WHERE后面符合的条件内容(比如WHERE 学号 = 2023000),代码是不会报错的。 - 如果不加
WHERE限制条件,DELETE会删除整个表格的所有数据内容(DELETE FROM <表名>),所以需要特别小心。
查询数据(查)
基本查询
我们可以使用SELECT来完成对表格中内容的查询:
SELECT * FROM <表名>;这样我们便可以在代码的输出结果中看到表格当前的内容了。
SELECT * FROM student;
其中SELECT后面的*表示的是输出表格中所有的字段,如果我们将*替换为学号, 姓名,那么输出的内容就不会包含性别字段的内容。
SELECT 学号, 姓名 FROM student;
一个比较有意思的是,SELECT后面不加表格,可以用来做一些简单的计算:
SELECT 100 + 50;
条件查询
与DELETE一样,SELECT也可以使用WHERE来作为条件语句进行查询操作。
SELECT * FROM <表名> WHERE <条件表达式>;如果条件有多个的时候,我们也可以使用AND,OR来连接多个条件。
我们先将刚刚删除的表格再增加一部分数据以保证表格数据的多样性。
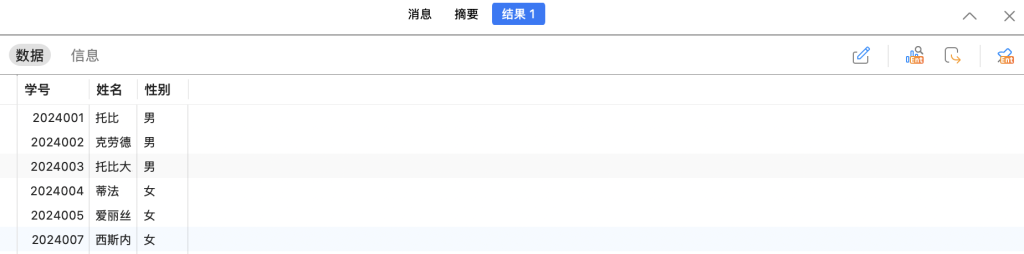
SELECT * FROM student WHERE 性别 <> '女' AND 姓名 = '托比';
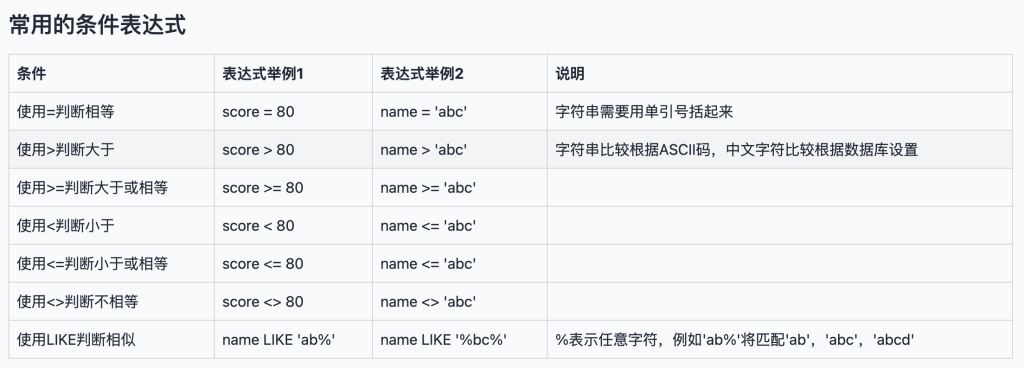
下面是 @廖雪峰的官方网站 中常用条件表达式子的总结:
模糊条件查询
当我们不完全确定要查询的内容时,我们可以使用LIKE进行查询。
SELECT * FROM <表名> WHERE <字段> LIKE '...%';其中我们就可以使用LIKE去表示我们不确定的字符,例如’托%’将匹配’托比’,’托比大王’。
SELECT * FROM student WHERE 姓名 LIKE '托%';
集合查询
IN 操作符用于检查某个值是否在指定的值集合中。它可以替代多个 OR 条件的写法,使查询更简洁。
IN的使用公式:
SELECT <列名> FROM <表名> WHERE <列名> IN (<值1>, <值2>, <值3>, …);比如我们可以使用IN来查询多个人的信息:
SELECT * FROM student WHERE 姓名 IN ('蒂法', '爱丽丝', '克劳德');
排序查询
一般我们在输出结果的时候,数据的排序都是按照主键也就是这里的学号进行排序的,如果我们需要不同的输出排序方式,便可以使用ORDER BY语句。
SELECT <字段1>, <字段2>, ... FROM <表名> ORDER BY <FROM前面的其中若干个字段> <DESC>;ORDER BY字段后面的DESC表示倒序排列,ASC表示正序(可以省略不写)。
如果前一个排序条件有相同,则会按后一个条件再次对相同的内容进行排序。
比如我们想查询student这个表格,并且按照姓名的倒序和性别的正序排列输出:
SELECT * FROM student ORDER BY 姓名 DESC, 性别;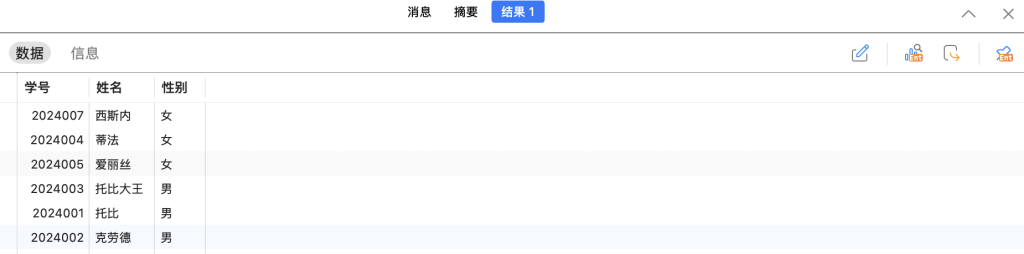
多表查询
多表查询的逻辑和单表查询是基本一致的,只是在FROM后面多填了若干个表名。
SELECT <若干字段名> FROM <表名1>, <表名2> WHERE <条件表达式>;值的注意的一个点是,两个表中说明字段的格式是表名.字段名。
我们在上面创建的score表中先简单写入数据。

我们可以这样查询各个表中我们需要的信息(这里由于score中的数据没有填完整,所以这里查询的时候,空白的数据就自动填充了):
SELECT student.学号, student.姓名, score.数据库 FROM student, score;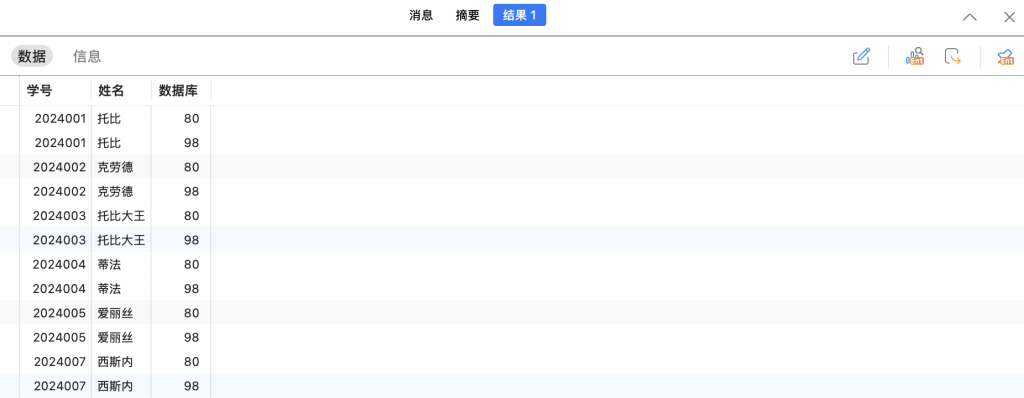
聚合查询
聚合查询可以让我们得到某一列的合计值、平均值、最大值和最小值等。
@廖雪峰的官方网站 中列了以上这几个聚合函数的说明:
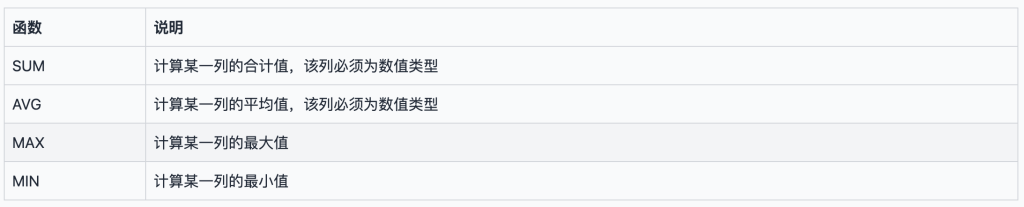
看表格的说明我们便可知其用处,SQL提供了专门的聚合函数,使用聚合函数进行查询,就是聚合查询,它可以快速获得结果。
并且使用聚合查询时,我们应该给列名设置一个别名,其主要用法如下:
SELECT <聚合函数>(<若干字段>) num FROM <表名>;这里我们就只以COUNT作为一个例子来说明:
SELECT COUNT(*) num FROM student WHERE 性别 = '女';
嵌套查询
嵌套查询(也称为子查询)是指在一个 SQL 语句中包含另一个 SQL 查询。子查询通常用于在主查询中提供一个结果集,帮助筛选、比较或汇总数据。嵌套查询的公式可以写为:
SELECT <列名> FROM <表名> WHERE <列名> <运算符> (<子查询>);比如我们想查询student表中一个人的信息,但是我们不知道他相关的信息,只知道他数据库的分数是98,但是这个分数的数据是在score当中的,所以这个时候我们可以使用嵌套查询进行数据的查找:
SELECT * FROM student WHERE 学号 = (SELECT 学号 FROM score WHERE 数据库 = 98);
更新数据(改)
最后我们使用UPDATE来修改更新表格当中的数据。其主要语法为:
UPDATE <表名> SET 字段1=值1, 字段2=值2, ... WHERE ...;WHERE前面是修改后的内容,WHERE后面是用于定位数据的条件。
比如我们想把原来student中托比大王的性别改成女,我们便可以像下面这样操作:
UPDATE student SET 性别 = '女' WHERE 姓名 = '托比大王';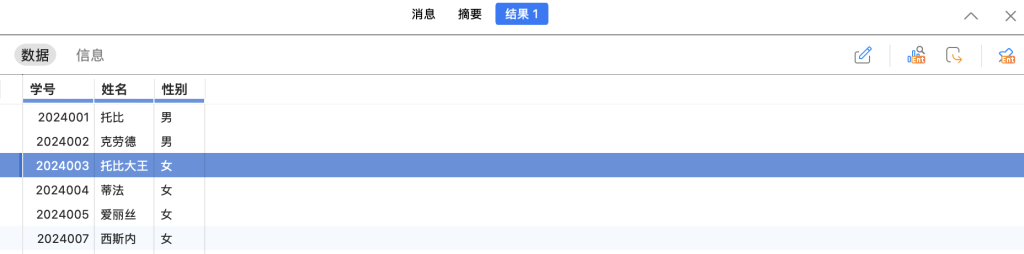
这里WHERE相关的逻辑也是和之前一样的,我们可以一次性更改表中的多个内容。比如我们想把学号小于等于2024004的性别都改成未知:
UPDATE student SET 性别 = '未知' WHERE 学号 <= 2024004;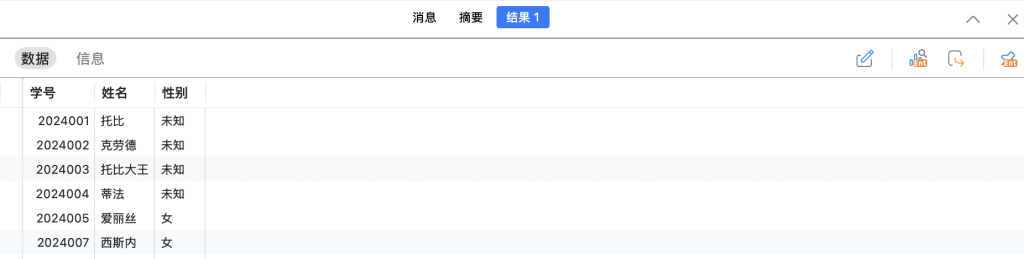
SQL中常见数据类型汇总
整数类型
- 迷你整型:
TINYINT,使用1个字节存储整数,最多存储256个整数(-128~127)
- 短整型:
SMALLINT,使用2个字节存储整数
- 中整型:
MEDIUMINT,使用3个字节存储整数
- 标准整型:
INT,使用4个字节存储整数
- 大整型:
BIGINT,使用8个字节存储
小数类型
- 单精度:
FLOAT,使用4个字节存储,精度范围为6-7位有效数字
- 双精度:
DOUBLE,使用8个字节存储,精度范围为14-15位有效数字
字符串类型
- 定长型:
CHAR(L),使用L指定固定长度的存储空间存储字符串
- 变长型:
VARCHAR(L),根据实际存储的数据变化存储空间
- 文本字符串:
TEXT/`BLOB`,专门用来存储较长的文本
- 枚举型:
ENUM, 一种映射存储方式,以较小的空间存储较多的数据
- 集合型:
SET,一种映射存储方式,以较小的空间存储较多的数据
日期类型
- 年:
YEAR,MySQL中用来存储年份的类型
- 时间戳:
TIMESTAMP,基于格林威治时间的时间记录
- 日期:
DATA,用来记录年月日信息
- 日期时间:
DATATIME,用来综合存储日期和时间
- 时间:
TIME,用来记录时间或者时间段


多疯了
期末看这个?
稳辣!