【MATCHER: SEGMENT ANYTHING WITH ONE SHOT USING ALL-PURPOSE FEATURE MATCHING】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
(2024.1.19)
与在各种语言任务中表现出色的大型语言模型不同,视觉基础模型在直接处理多样化的感知任务时面临限制。
本文提出Matcher能够通过使用上下文示例来分割任何物体。
Matcher 是一个无需训练的框架,它通过整合通用特征提取模型(DINOv2)和类无关分割模型(SAM)来实现一次性分割。给定一个上下文示例,包括参考图像和掩模,Matcher 可以对目标图像进行分割,提取与参考图像相同的语义对象或部分。

Matcher 框架由三个主要组件构成:对应矩阵提取 (Correspondence Matrix Extraction, CME)、提示生成 (Prompts Generation, PG)、可控掩模生成 (Controllable Masks Generation, CMG)。
对应矩阵提取 (CME):使用现成的图像编码器提取参考图像和目标图像的特征。计算两个图像特征之间的相似度,以发现参考掩模在目标图像上的最佳匹配区域。定义了一个对应矩阵S,用于表示参考图像和目标图像特征之间的余弦相似度。
提示生成 (PG):利用密集的对应矩阵,通过双向匹配和多样化的提示采样器来生成高质量的点和框指导,以便于可提示的分割。Patch-Level Matching用来提出双向匹配策略,以消除匹配异常值。Robust Prompt Sampler用于基于匹配点的位置,使用 k-means++ 聚类方法将匹配点分成多个簇,并从这些簇中采样不同类型的提示子集,包括部分级提示、实例级提示和全局提示。
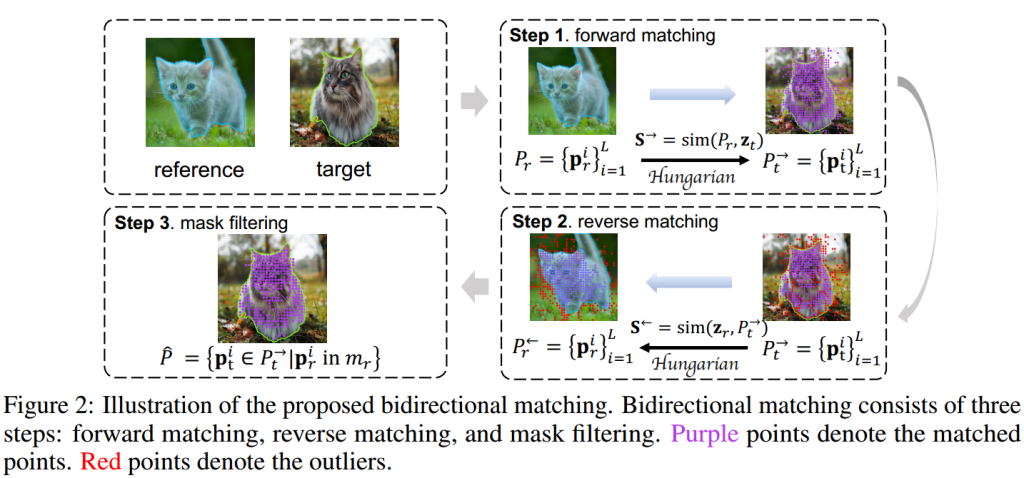
双向匹配:包括前向匹配、反向匹配和掩模过滤三个步骤,旨在生成高质量的点提示和框提示。前向匹配在参考掩模和目标图像特征之间找到匹配点,反向匹配在匹配点和参考图像特征之间进行,最后通过掩模过滤去除异常值。
可控掩模生成 (CMG):通过实例级匹配模块从掩模提议中选择高质量的掩模,然后合并这些选定的掩模以获得最终目标掩模。Instance-Level Matching使用最优传输问题和地球移动者距离 (EMD) 来计算掩模内密集语义特征之间的结构距离,以确定掩模的相关性。
实验部分:
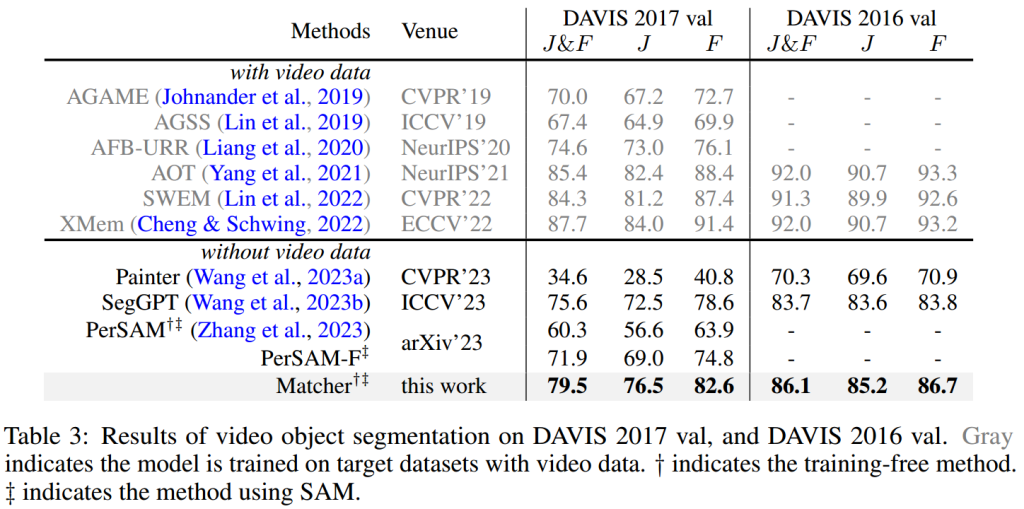
在所有实验中,Matcher 没有进行任何训练。输入图像的大小分别为一次性语义分割和物体部分分割 518×518 像素,视频物体分割 896×504 像素。
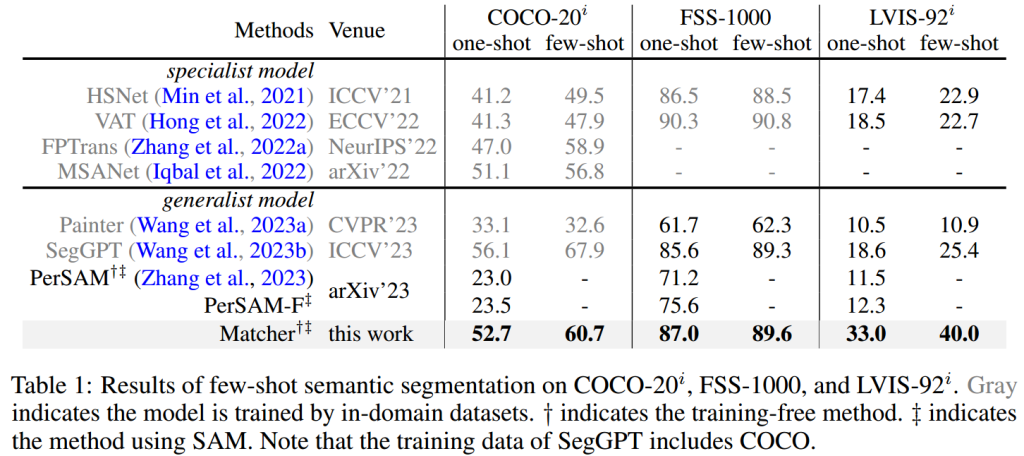
数据集:COCO-20i、FSS-1000和LVIS-92i
评估指标:mIoU、J&F分数
一次性语义分割结果:
一次性物体部分分割: