【Segment Any Anomaly without Training via Hybrid Prompt Regularization】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
(2023.5.18)
异常分割模型在工业质量控制和医学诊断等领域具有重要应用,可靠的异常分割的关键是区分异常数据和正常数据的分布。
现有的异常分割模型通常依赖于特定领域的微调,这限制了它们在无数异常模式中的泛化能力。
本文考虑了图像上的零样本异常分割(zero-shot anomaly segmentation, ZSAS),这是一个很有前途但尚未开发的方法,即在训练过程中不为目标类别提供正常和异常图像。
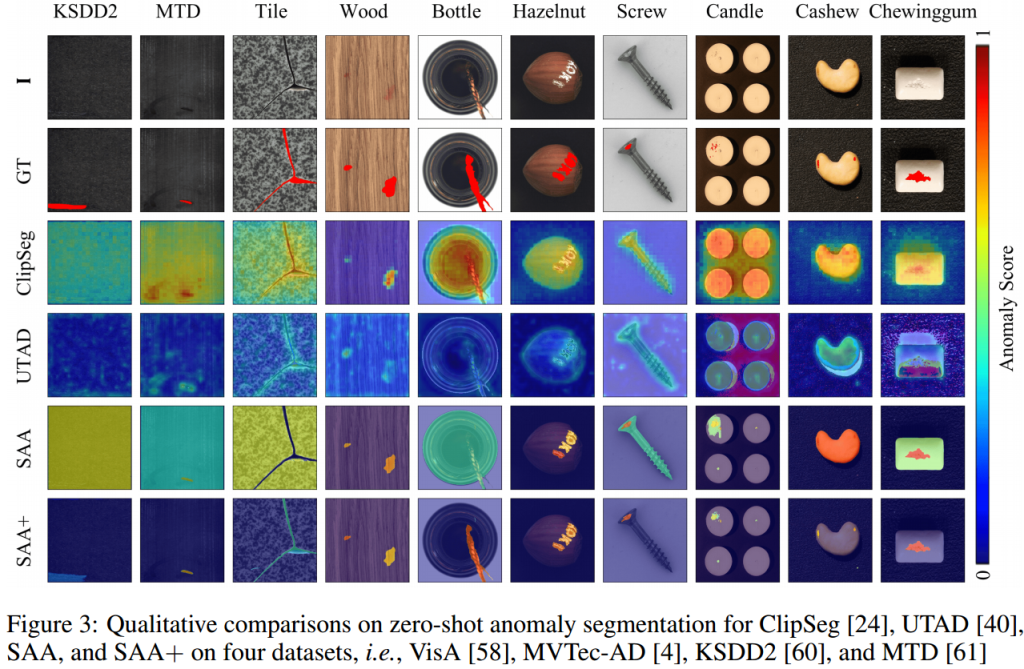
文章提出了SAA框架,允许在不需要训练的情况下协作组装不同的基础模型进行异常分割。然而,SAA显示出严重的虚警问题,因此,本文在改进的模型(SAA+)中进一步加强了混合提示的正则化,成功地帮助识别了异常区域。

SAA: Vanilla Foundation Model Assembly for ZSAS 零样本异常分割
SAA模型有两个主要的部分:异常区域生成器(Anomaly Region Generator)和异常区域细化器(Anomaly Region Refiner)。
异常区域生成器:通过语言提示来检索图像中的对象。给定描述要检测区域的语言提示,基础模型可以为查询图像生成所需区域。使用一个预训练在大规模语言-视觉数据集上的模型(如GroundingDINO),该模型通过文本编码器和视觉编码器提取语言提示和查询图像的特征,然后通过跨模态解码器生成粗略的对象区域(边界框)。
异常区域生成器模块的定义如下:

异常区域细化器:为了生成像素级的异常分割结果,提出使用一个高级的基础模型(SAM)来细化边界框级别的异常区域候选。该模型包括基于ViT的骨干网络和一个条件掩码解码器,它在大规模图像分割数据集上进行了训练,能够生成高质量的掩码。细化器接受各种类型的提示作为输入,并将边界框候选作为提示,以获得像素级的分割掩码。
异常区域细化器的定义如下:

初步实验表明,尽管SAA解决方案简单直观,但它存在语言歧义问题,某些语言提示(如“异常”)可能无法检测到所需的异常区域。
语言歧义问题归因于预训练语言-视觉数据集与目标ZSAS数据集之间的领域差异,以及在大规模数据集中缺乏对“异常”这种形容词的表达。
为了解决语言歧义问题,文章提出了SAA+。
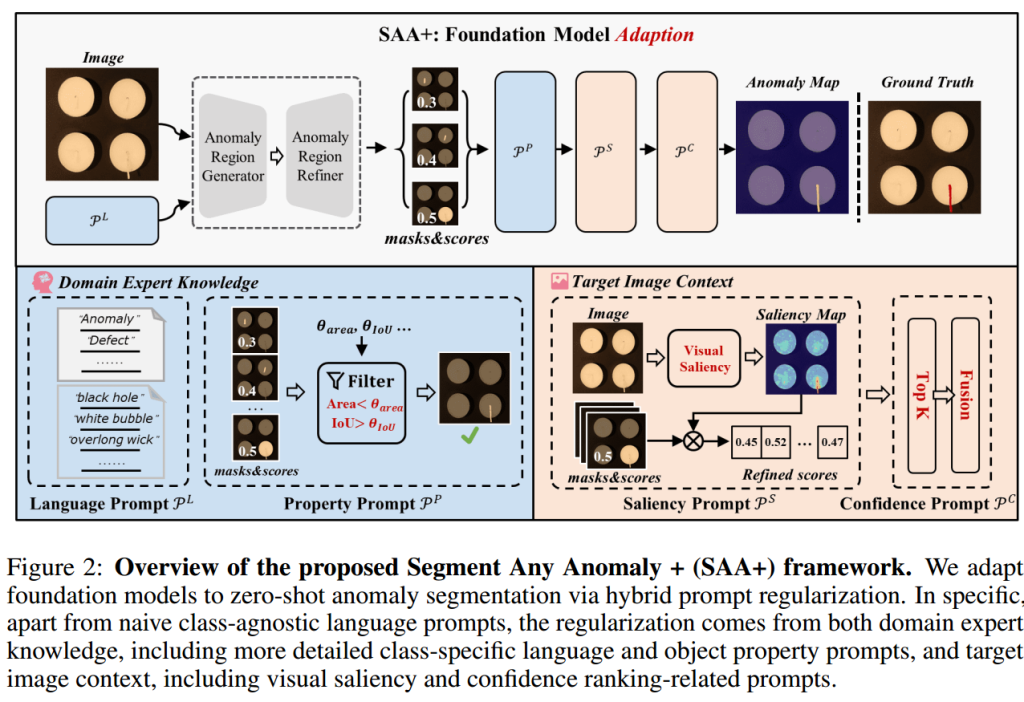
根据SAA的问题,SAA+加入了两个模块:领域专家知识生成的提示和从目标图像上下文派生的提示。
领域专家知识生成的提示:为了解决语言歧义问题,利用领域专家的知识来生成更精确的提示,主要的提示有异常语言表达作为提示和异常对象属性作为提示。
目标图像上下文派生的提示:除了利用领域专家知识外,还可以利用输入图像本身提供的信息来提高异常区域检测的准确性。本文提出了异常显著性作为提示和异常置信度作为提示两种方式。
实验部分:
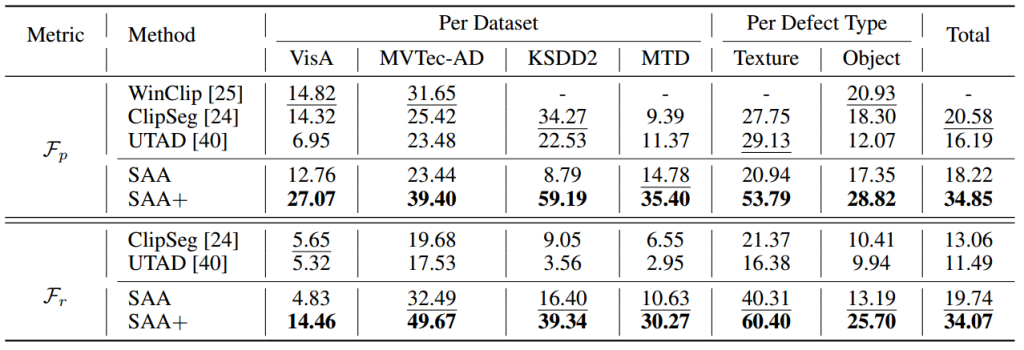
使用了四个具有像素级注释的数据集:VisA、MVTec-AD、KSDD2和MTD。这些数据集包括电路板等多种物体子集,以及地毯等纹理异常。
评估指标主要有:
max-F1-pixel (Fp):在最优阈值下,衡量像素级分割的F1分数。
max-F1-region (Fr):为了减轻对大缺陷的偏见,作者提出了这个指标,计算在最优阈值下的区域级分割的F1分数,只有当重叠值超过0.6时,预测才被视为正。