【进一步改进与决策树】吴恩达机器学习笔记EP9(P81-P90)

从今天开始我将学习吴恩达教授的机器学习视频,下面是课程的连接1.1 欢迎来到机器学习!_哔哩哔哩_bilibili。一共有142个视频,争取都学习完成吧。
误差分析
除了偏差和方差以外,误差分析也对决定模型的下一步改进有帮助。
误差分解就是去修改模型分类中错误的地方。如果错误的数量比较少,就可以手动查看并对其分类。
如果错误的数据量过大,可以手动抽取一个子集,可以通过这部分提供常见的错误类型的统计数据,并在此集中注意力。
误差分析的局限性就是对人类不擅长的任务来说,错误分析是困难的。

添加数据
一般的神经网络模型,数据越多,训练的效果就越好。
所以可以修改现有的数据集,从而增加新的数据(图像、音频等领域都适用)。
如下图这种方式就是数据增强。

也可以通过合成数据来增加数据量,利用计算机合成制造更多的数据。

迁移学习:使用其他任务中的数据
当训练数据量过少的时候,可以用其它大量不太相关的数据预训练模型。
我们可以在大量不太相关的数据中训练得到一个预训练过的模型。然后可以冻结其它层,使用自己少量的数据集去训练输出层;也可以在预训练的基础上,再次训练所有的层。
这两种方法也被称之为监督预训练和微调。
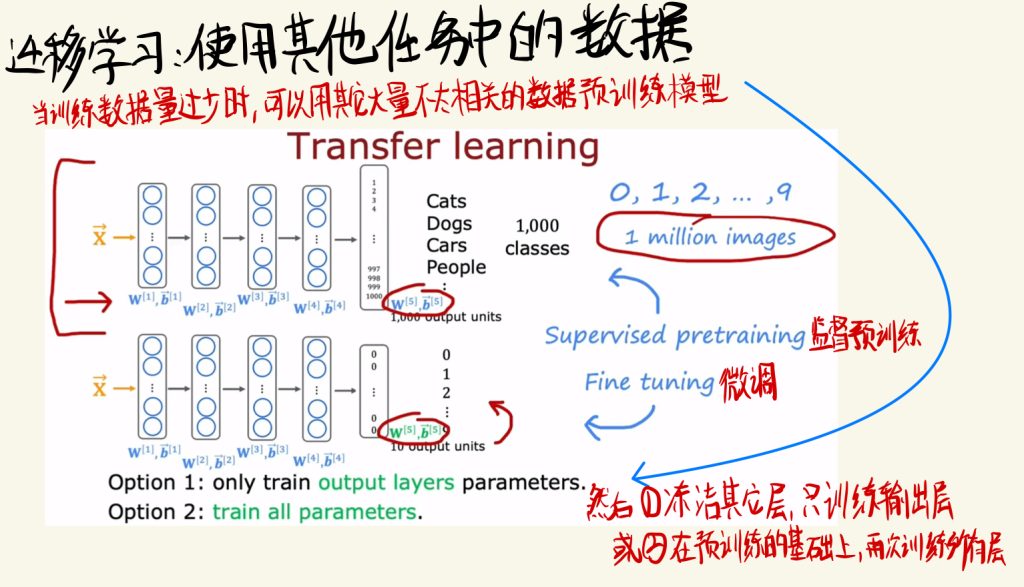
使用不相关的数据预训练模型的有效性解释是:用大量不相干的数据预训练模型可以让模型学到图像中通用的边缘、角落、曲线或基础形状的知识。
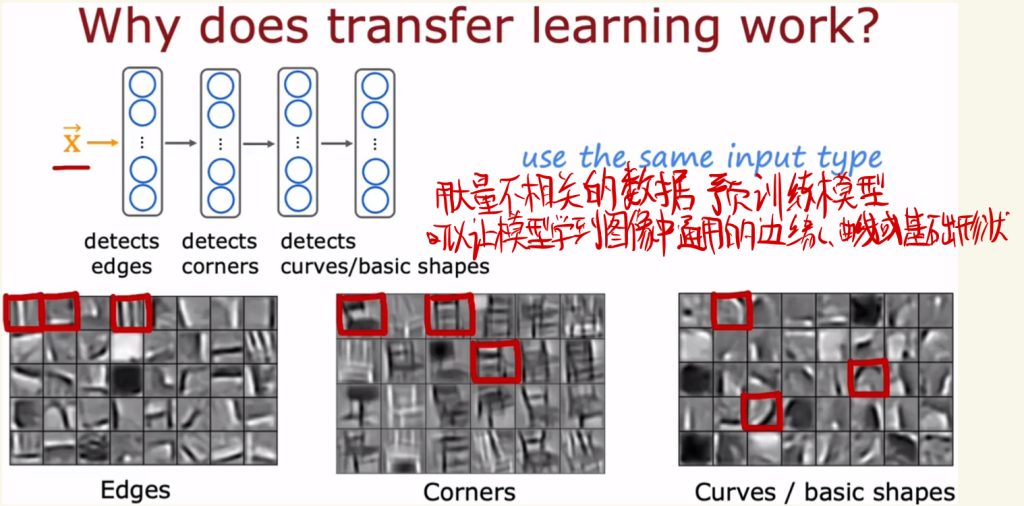
下面对迁移学习的步骤简单总结。首先先在网络上下载别人预训练好的神经网络模型,然后用自己的数据微调模型。这样可以用少量的数据训练出效果较好的模型。

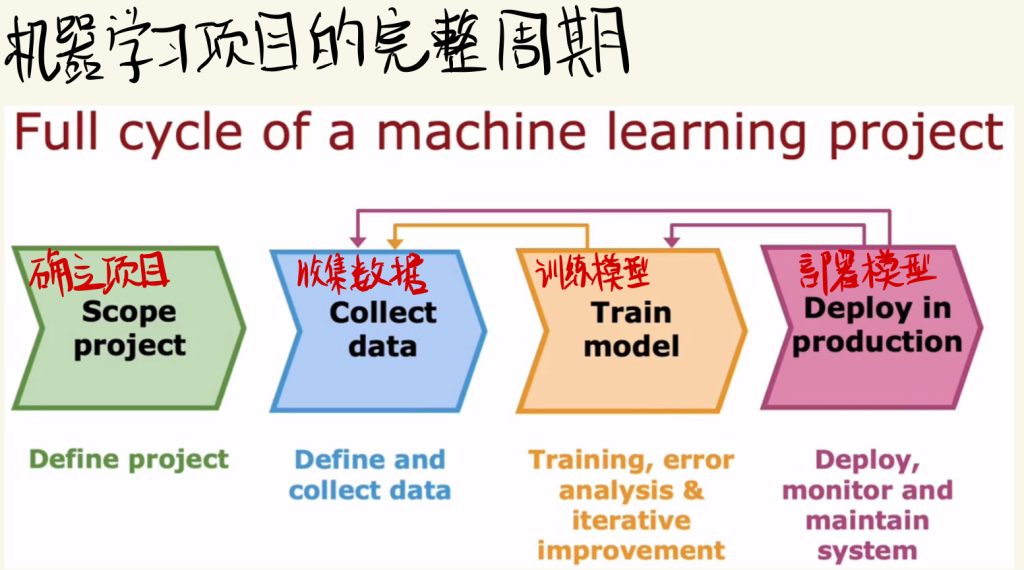
机器学习项目的完整周期
下面就是机器学习项目的完整周期介绍:
首先确立项目,然后收集相关数据,再训练模型,最后部署模型。
如果训练模型或者部署模型时遇到问题,都可以往前回溯,重新根据问题进行之前的操作改进。
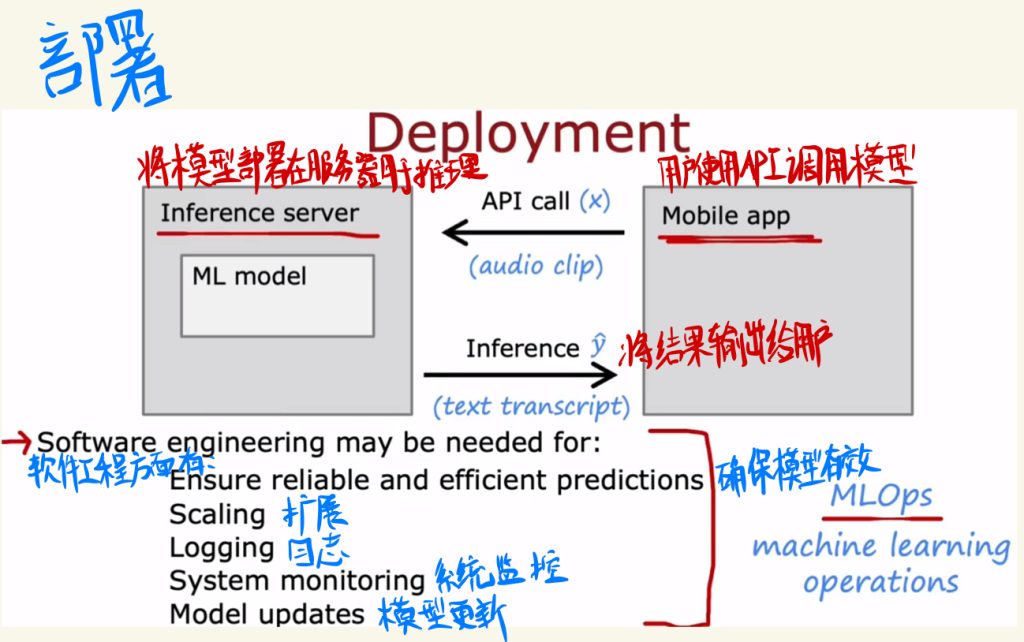
下面时模型的部署。
一般会将模型部署在服务器上进行推理,然后用户调用API使用模型,在服务器上推理完成之后将结果再输出给用户。
一般部署在软件工程方面需要有:
确保模型的有效
扩展
日志
系统监控
模型更新
机器学习公平、偏见与伦理
机器学习中需要考虑训练出来的模型的偏见和不良使用问题。

下面是一般性防止上面两个问题的指导:

倾斜数据集的误差指标
分类问题中,如果两边的数据集差异过大,就会出现问题。
一个极端的例子,如果训练集中有99%的数据y是0,这个时候一个很垃圾的模型,不管输入什么,输出都是0的模型的准确率可以达到99%,这绝对比正常训练的模型准确率还要高。

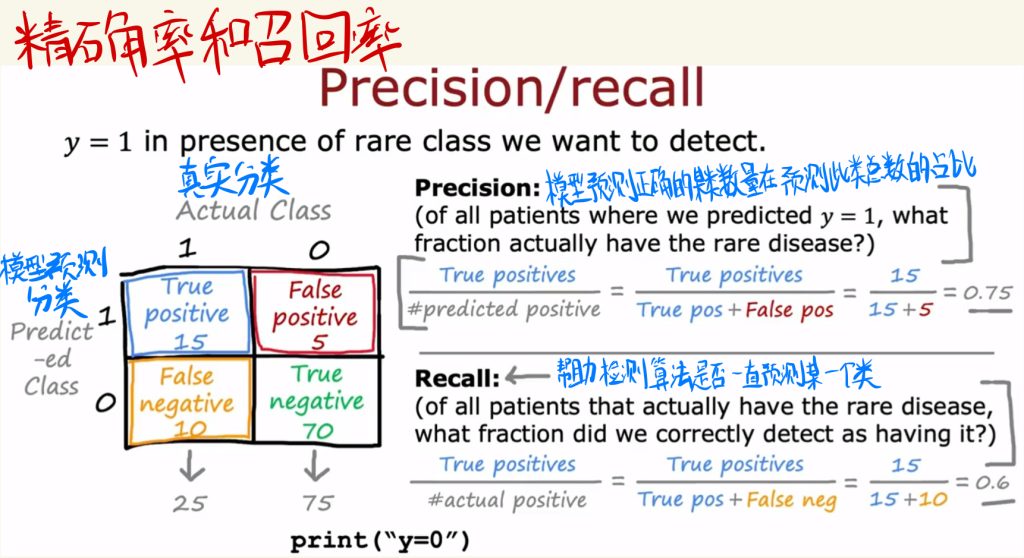
精确率和召回率是衡量数据中两类数据平衡的指标。
准确率是模型预测正确的某类数量在预测此类总数的占比。
召回率可以帮助检测算法是否一直预测某一个类。
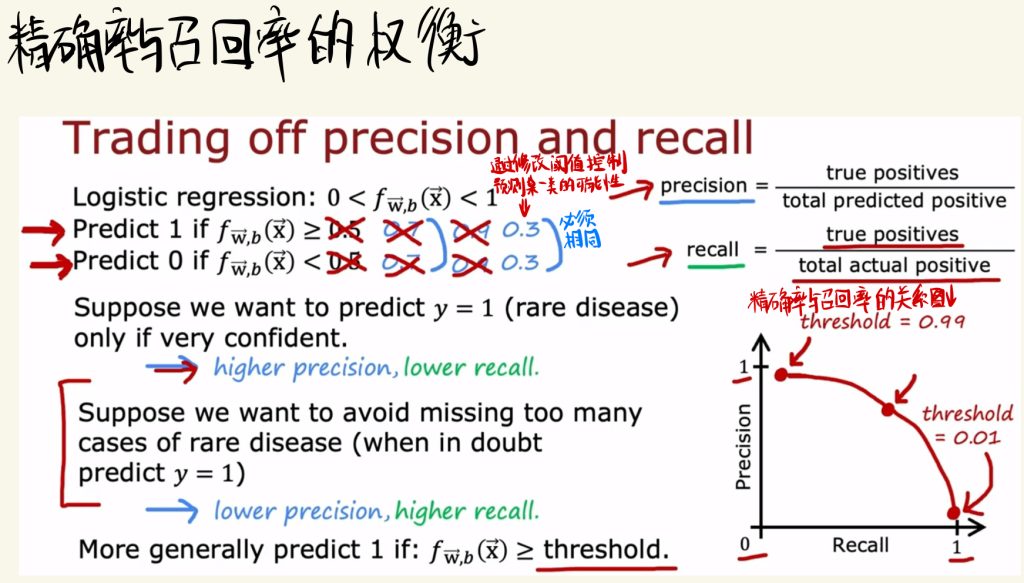
精确率与召回率的权衡
通过修改阈值可以控制预测某一类的可能性。
下面是精确率和召回率之间的关系图以及其对应的阈值。
F1分数可以结合衡量精确率和召回率,并且着重数值较低的那个量。
通过F1值可以很好的看出数据的分布情况,下面是F1数值的计算方法:

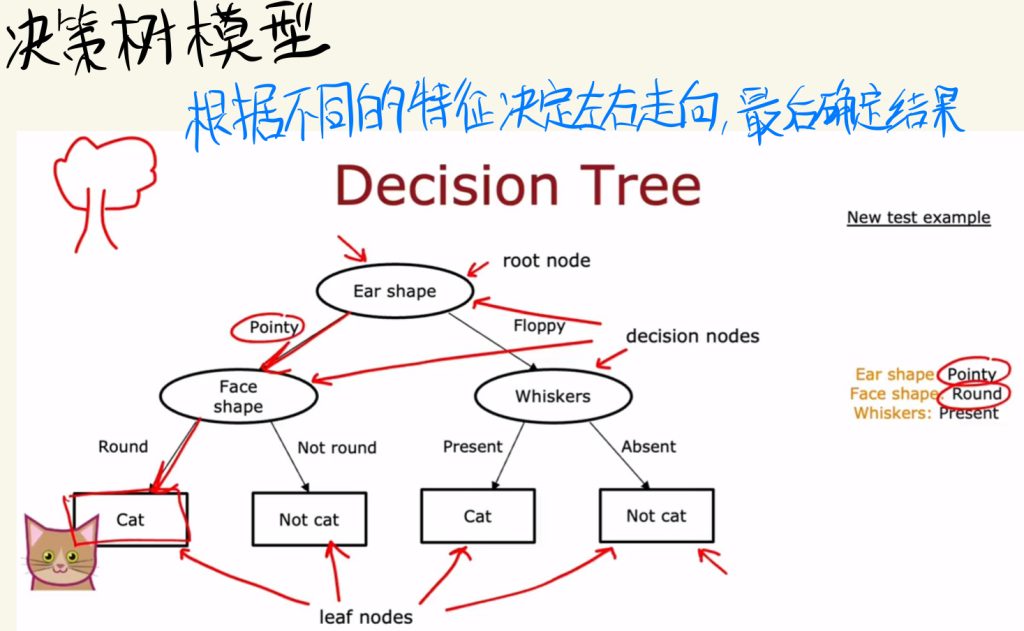
决策树模型
决策树模型是神经网络之外的另一种模型。
决策树可以根据不同的特征去决定左右走向,最后确定结果。
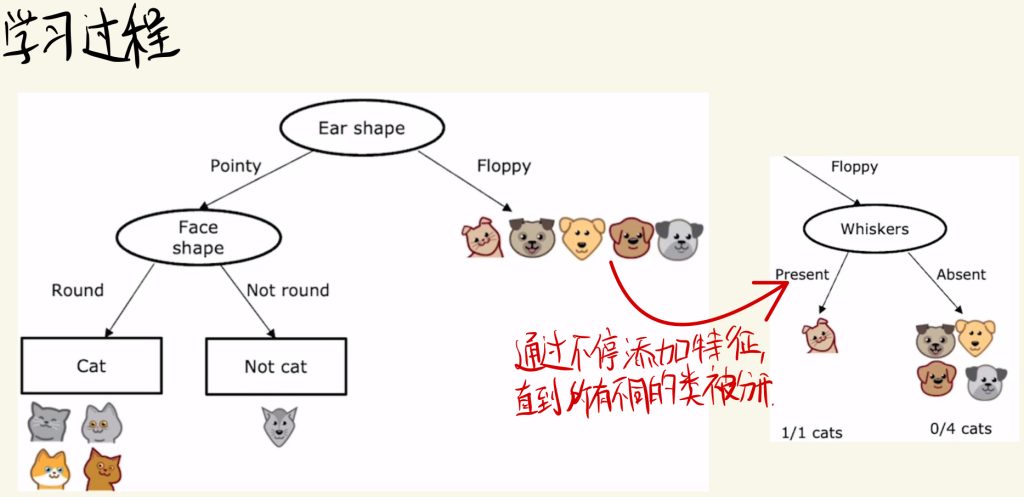
学习过程
决策树的学习过程通过不断添加特征,直到所有不同的类被分开。
所以对于决策树模型有以下两个决定:
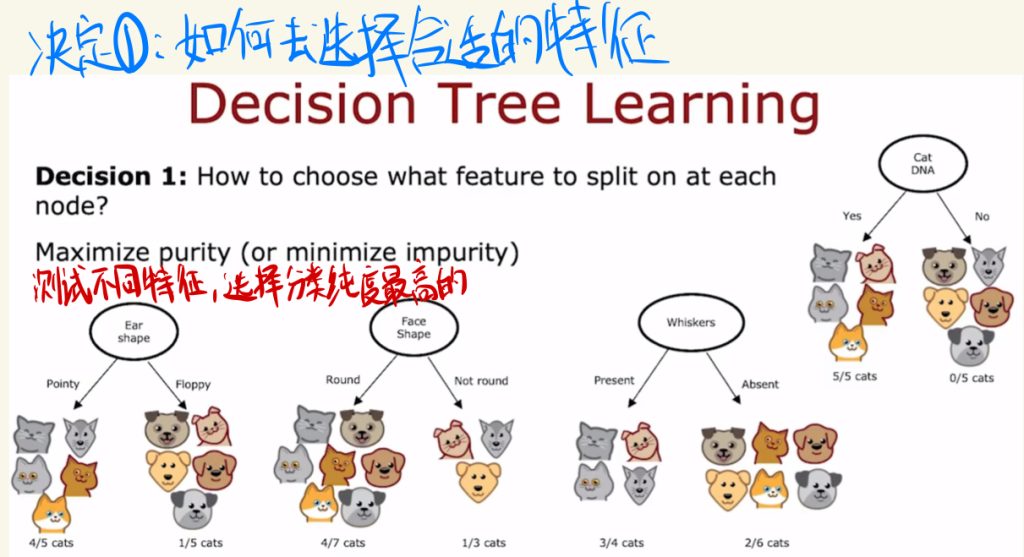
决定1:如何去选择合适的特征。
可以测试不同特征,选择分类纯度最高的特征。
决定2:何时停止分裂数据。‘
当节点100%为一个类时
分裂节点超过树的最大深度时
纯度低于某个阈值时
当一个节点的样例数低于阈值时

测量纯度
Entropy 熵可以衡量纯度,一组中同种类占比越大,熵越大。
下面时熵的计算公式:



