【Adapting the Segment Anything Model During Usage in Novel Situations】
本篇文章是个人看文献的一些总结和个人的想法,都是个人看过文章之后的理解,不保证一定是对的,如果我的理解有错,欢迎纠正。
(2024.4.12)
在需要特定数据的领域,如体育、农业、医学图像分割和机器人视觉。这些系统通常通过用户交互,如点击、涂鸦、边界框和粗糙掩模等,来创建掩模,因此交互式分割的系统是重要的。
交互式分割问题的精确描述中用户通过与神经网络交互,提供指示前景或背景的点击,以创建分割图。这个过程是迭代的,直到用户对掩模的质量满意为止。SAM对于特定的图像领域和不太常见的对象类型,仍有改进空间。
为了解决SAM在新领域或不常见对象上的交互式分割任务中的性能下降问题。文章提出了一种适应性框架,这个框架通过在模型使用过程中实时地适应用户交互和生成的掩模来改进性能。
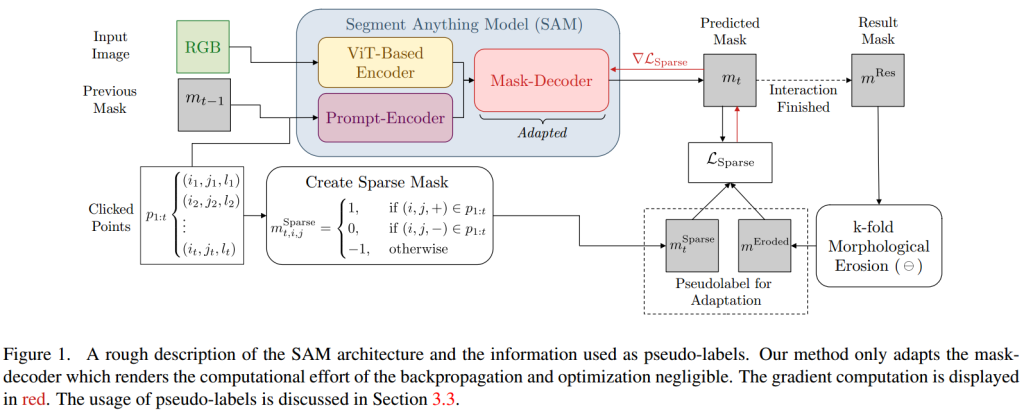
框架依赖于用户在交互式分割过程中提供的点击(clicks),这些点击指示了图像中属于前景或背景的像素位置。
使用用户点击作为单个像素的伪标签,以及通过交互过程得到的掩码,生成用于训练的伪标签。
文章在适应框架中提出了几种适应策略:
立即使用点击进行适应:用户每次点击后,都可以使用到目前为止收集的所有点击来创建一个稀疏掩模,并立即进行优化步骤,从而逐渐过度拟合到特定图像。
使用所有点击适应图像序列:在完成图像注释后,使用所有点击来创建单个稀疏掩模,并进行单一优化步骤,以适应测试集中的对象类型和图像领域。
使用结果掩模适应图像序列:使用用户认为质量足够的交互式创建的掩模作为伪标签来适应模型。为了避免错误区域,首先对掩模进行形态腐蚀处理,然后使用腐蚀后的掩模作为伪标签。
为多类使用多个解码器:由于适应过程可能会导致模型过度拟合到特定领域或对象类型,文章提出复制解码器的参数,为每个不同的类别分别适应。
只优化SAM模型中负责解码的部分,而不是整个网络。这样做可以减少计算成本,并保持实时性能。
实验部分:
使用两个主要指标来评估交互式分割系统的性能:Number of Clicks (NoC) 和 Failure Rate (FR)。NoC衡量在达到特定IoU阈值TIoU内的点击次数,而FR衡量在合理点击次数内无法完成分割的图像的百分比。
文章在多个数据集上测试了SAM的性能,这些数据集包含了不常见或稀有的对象类型。数据集包括Rooftop、DOORS、TrashCan、CAMO、ISTD、LeafDisease、PPDLS和TimberSeg等。他们使用NoC20@85和FR20@85指标来评估模型性能,即在20次点击内达到85% IoU的点击次数和失败率。


在医学图像分割任务中测试了适应性方法,使用了KvasirInstrument、CVCClinicDB、GlaS和KvasirSeg四个不同的数据集。

