【分类与正则化】吴恩达机器学习笔记EP4(P31-P41)

从今天开始我将学习吴恩达教授的机器学习视频,下面是课程的连接1.1 欢迎来到机器学习!_哔哩哔哩_bilibili。一共有142个视频,争取都学习完成吧。
分类
二进制分类就是yes or no的问题,输出的结果用0和1表示。
通常0表示negative的一类,1表示positive的一类。

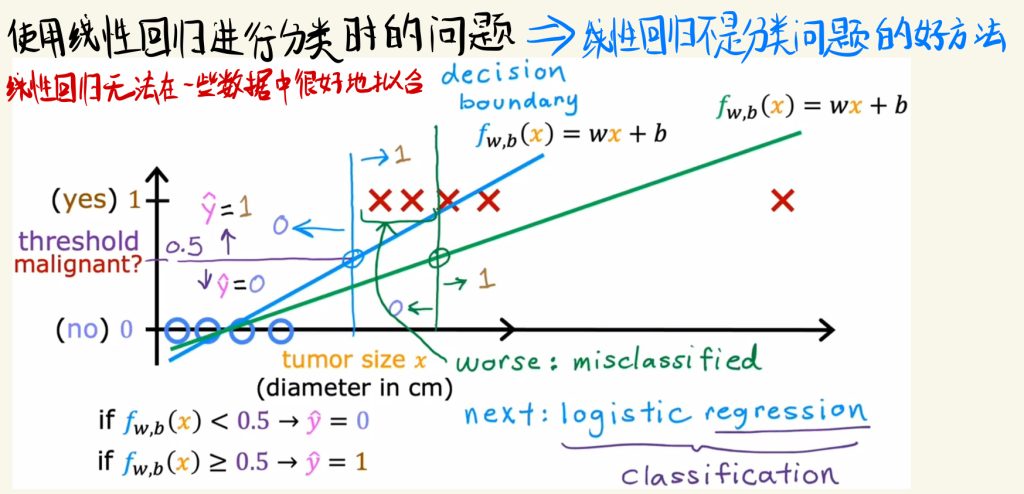
使用线性回归进行分类时的问题
使用线性回归进行分类时的问题是线性回归无法在一些数据中很好地拟合数据。
因此线性回归不是解决分类问题的好方法。
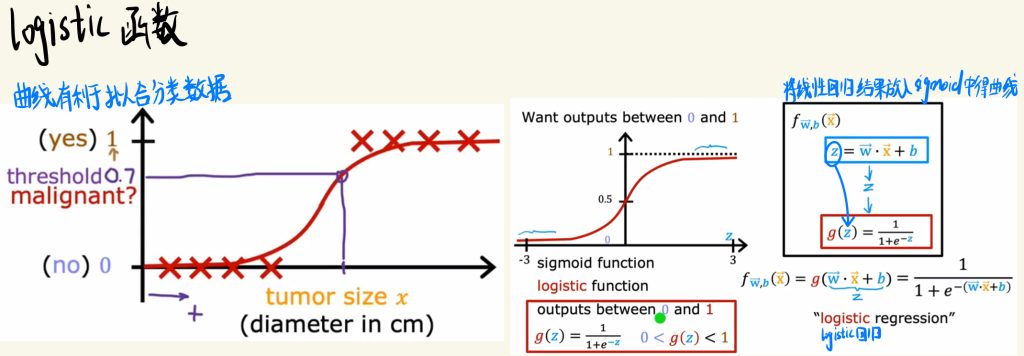
logistic函数
曲线有利于拟合分类的数据。
这里提出一个乙状型的函数——sigmoid。将线性回归的结果放入sigmoid中可以获得曲线。
如下图这种曲线的模型也称之为logistic回归。
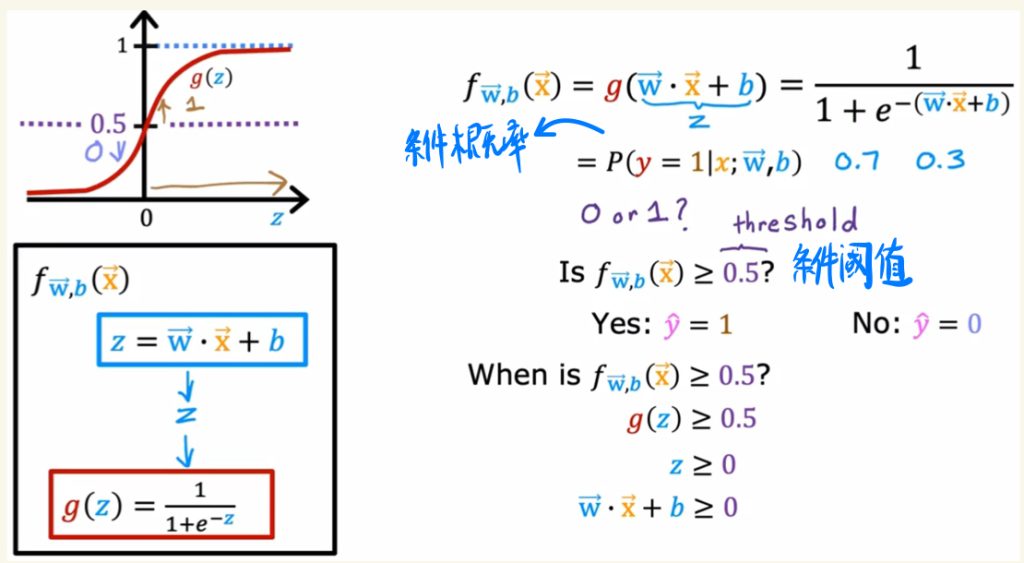
下面是条件概率的写法。
logistic回归的f模型也可以看作是一个条件概率。
比如模型的值大于或小于某个值就输出不同的结果,这个值称之为条件阈值。
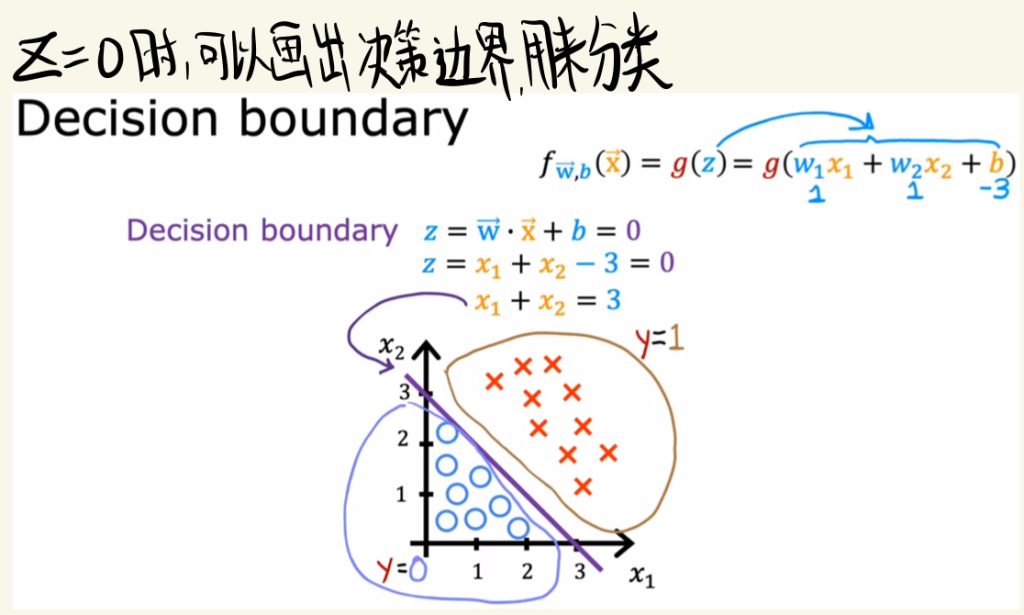
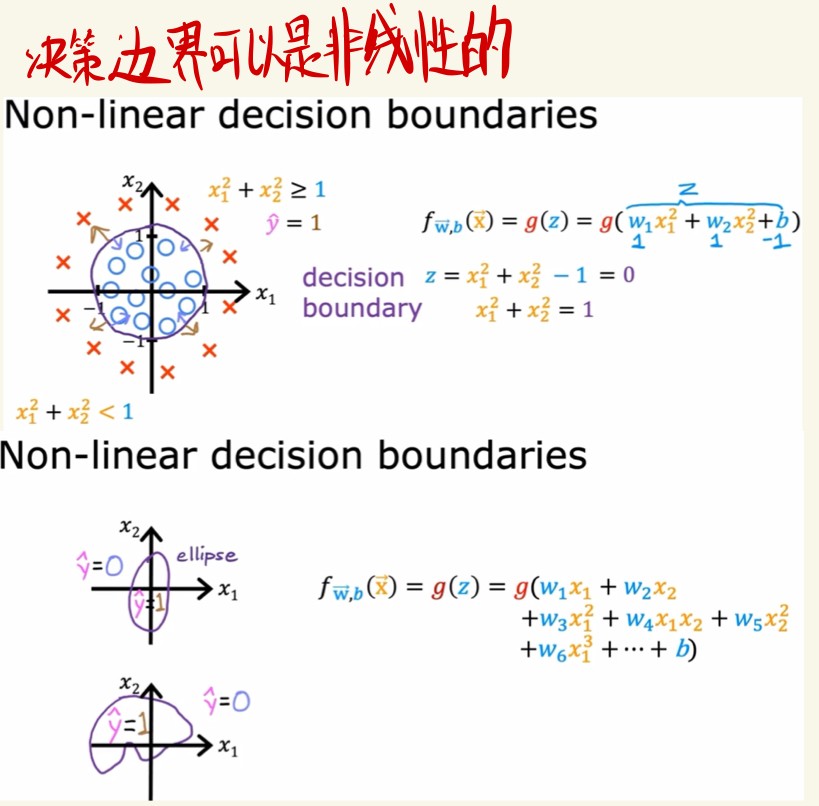
决策边界
z = 0时,可以画出决策边界,边界的一边和另一边是不同的类。
决策边界也可以是非线性的。
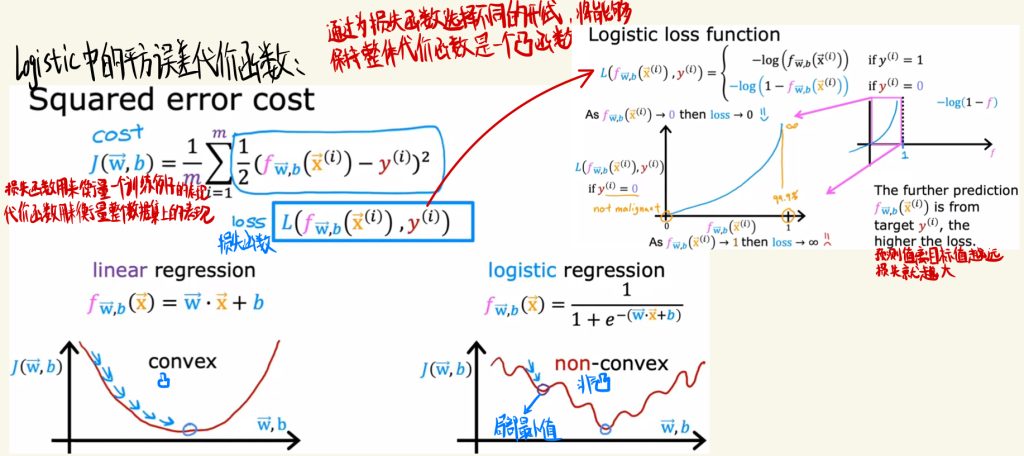
logistic中的平方误差代价函数与损失函数
如下图是logistic中的平方误差代价函数。
线性回归的图是convex的形状,但是logistic回归是non-convex的,图像弯弯曲曲而且会有局部最小值。
拿出函数求和里面的那部分就可以拿来写作损失函数。通过为损失函数选择不同的形式,将能够保持整体代价函数是一个convex函数。
预测值离目标值越远,损失函数就越大。
损失函数用来衡量一个训练例子的表现。
代价函数用来衡量这个数据集上的表现。
简化损失函数写法
因为随着输出y的不同,损失函数有不同的写法,会导致之后的处理很麻烦。
因此通过一些数学变换,将损失函数写成如下图所示。这样无论y是什么,损失函数都可以写成一个式子。

简化代价函数的写法
将简化的损害函数带入代价函数就可以得到简化的代价函数。

logistic回归的梯度下降
logistic回归的梯度下降和之前的线性回归下降差不多。
利用代价函数的导数,同时更新参数。
两者之间唯一的不同点是f(x)的定义不同。

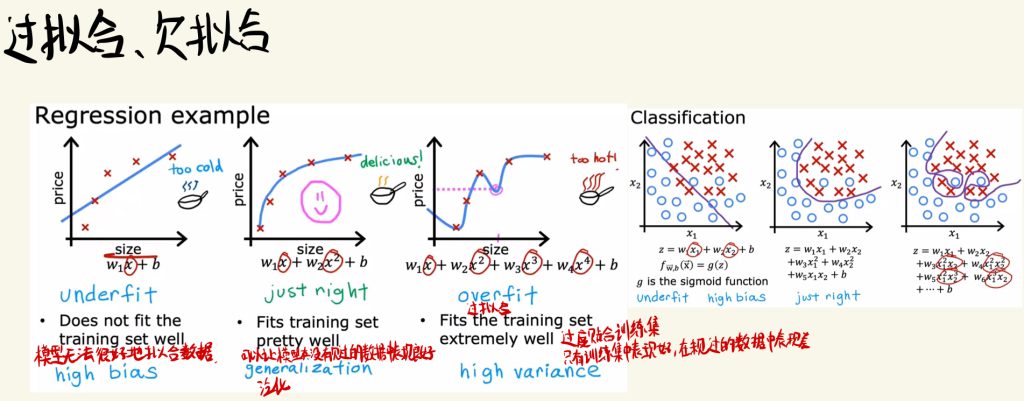
过拟合与欠拟合
模型无法很好地拟合数据称之为欠拟合。
可以让模型在没有见过的数据中表现良好的就是好模型,这种能力也称之为泛化。
过拟合就是过度贴合训练集,只有训练集中表现好,在从未见过的数据中表现差。
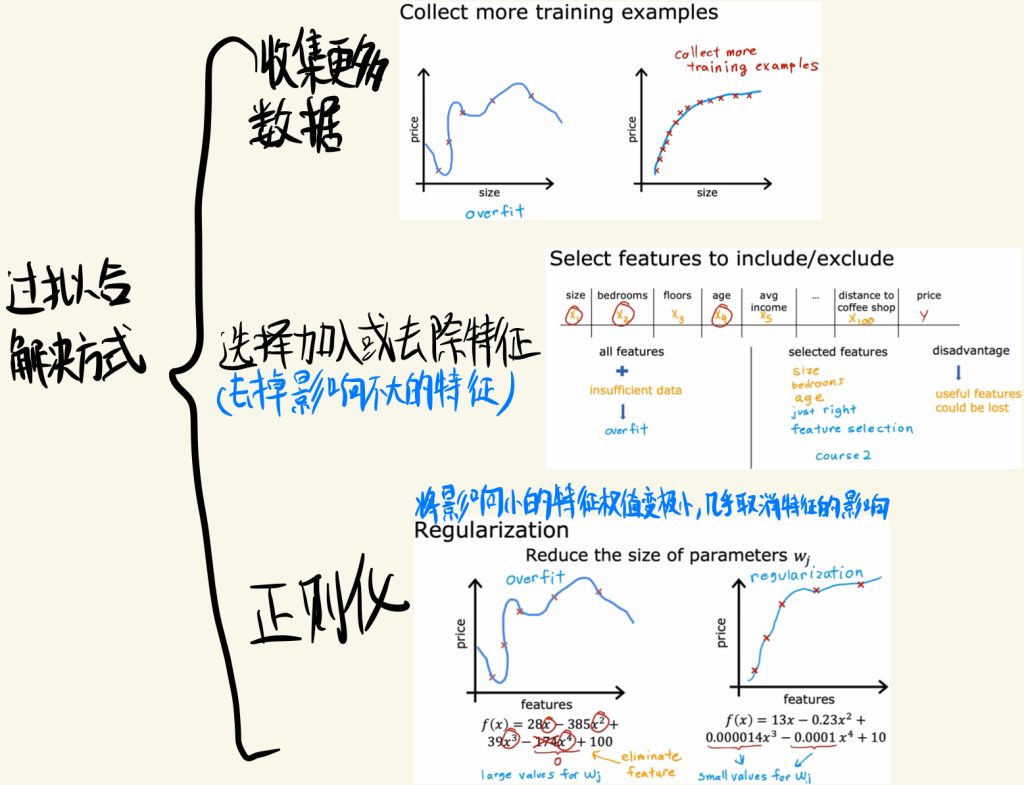
过拟合的解决方式
过拟合的解决方法可以有下面三种:
(1)收集更多的数据
(2)选择加入或去除特征(去掉影响不大的特征)
(3)正则化:将影响小的特征权值变得极小,几乎取消了该特征的影响
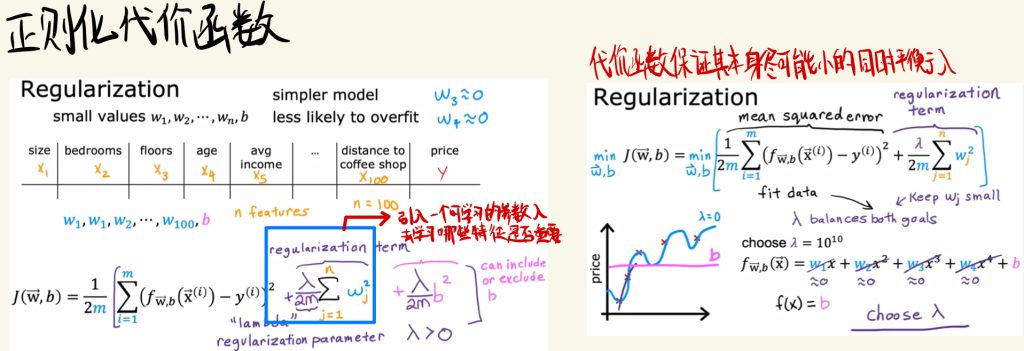
正则化代价函数
在代价函数中引入一个可学习的参数λ,去学习哪些特征是否重要。
代价函数要保证其本身尽可能小的同时平衡λ。
正则化线性回归
正则化线性回归在梯度下降时,在导数中增加正则化模块,对于b参数的更新无需添加。

正则化logistic回归
高阶多特征的z容易发生过拟合。
和线性回归的正则化类似,也是在原代价函数中添加正则化。
正则化的梯度下降类似于线性回归的正则化梯度下降。

